Type one paragraph describing a game. A few minutes later, click run. A real Phaser 4 scene loads inside your browser tab — you move, you jump, you collide, you take damage, you restart. That is what prompt to game AI means in 2026, and the “a few minutes later” clause is no longer aspirational. The trick is that there is no single “prompt to game AI” pipeline; there are at least four, with different speed, cost, and quality trade-offs. This guide walks the four pipelines you can drive inside WizardGenie today, what each one ships, when each one wins, and how to pick the right model on the typing side so the trial does not vaporise on the first iteration. Verified May 12, 2026.
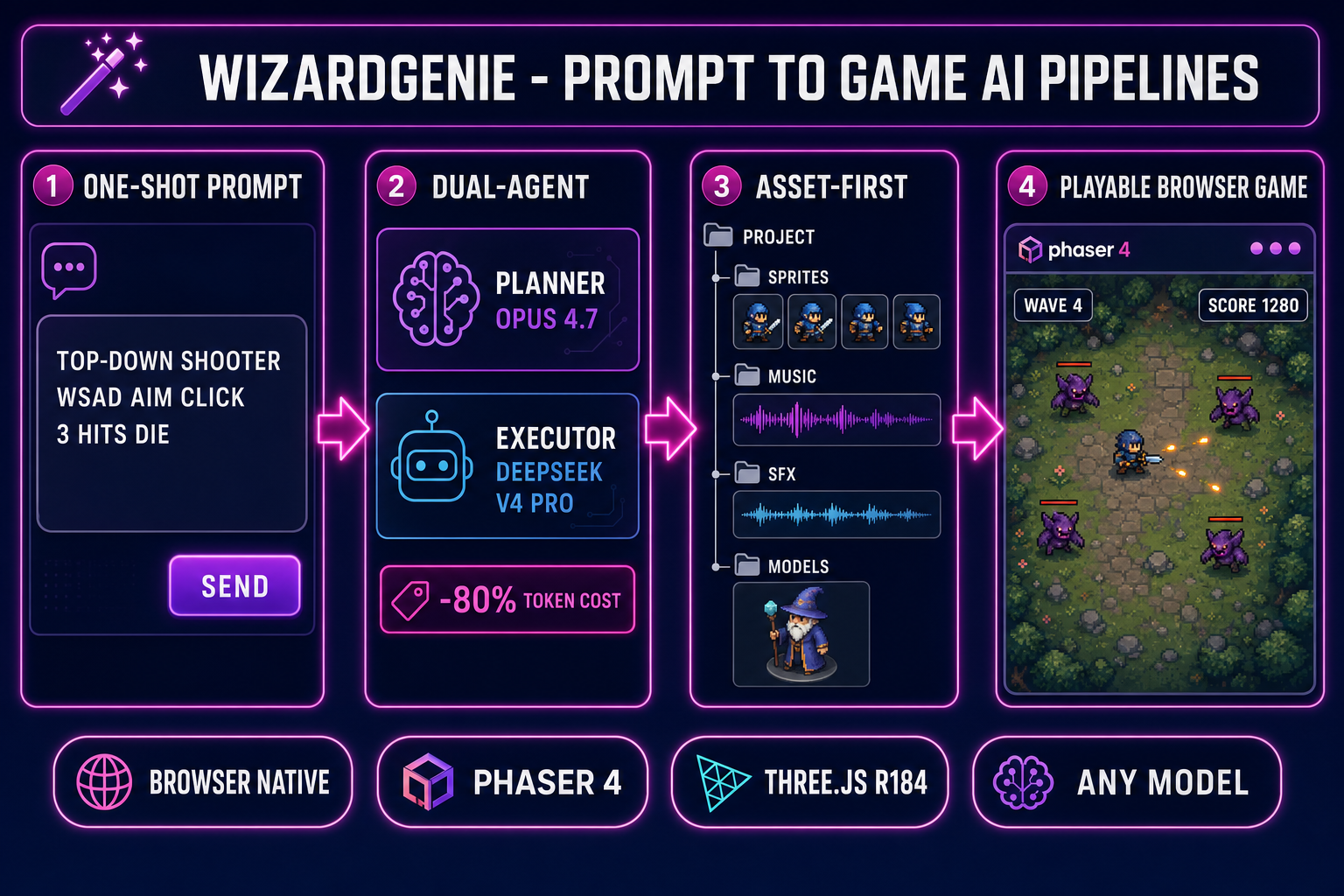
The four prompt-to-game AI pipelines at a glance
Before walking each pipeline in detail, the comparison: which one to pick depends on whether you want speed, cost-control, asset quality, or a known genre baseline. The four pipelines and the one-line case for each:
- One-shot prompt-to-playable. Type one paragraph, hit run, get a playable scene. Best for the first prototype of a new idea or a quick jam-day starter. Fastest path to “does this concept feel right”; weakest path for production polish. Five minutes end to end.
- Dual-agent Planner+Executor. One expensive reasoning model plans, one cheap fast model types. Best for medium-length sessions where you want frontier-quality decisions but do not want to pay frontier-quality token rates on the entire output. Costs roughly one-fifth of single-frontier on the same project. Twenty to ninety minutes per iteration.
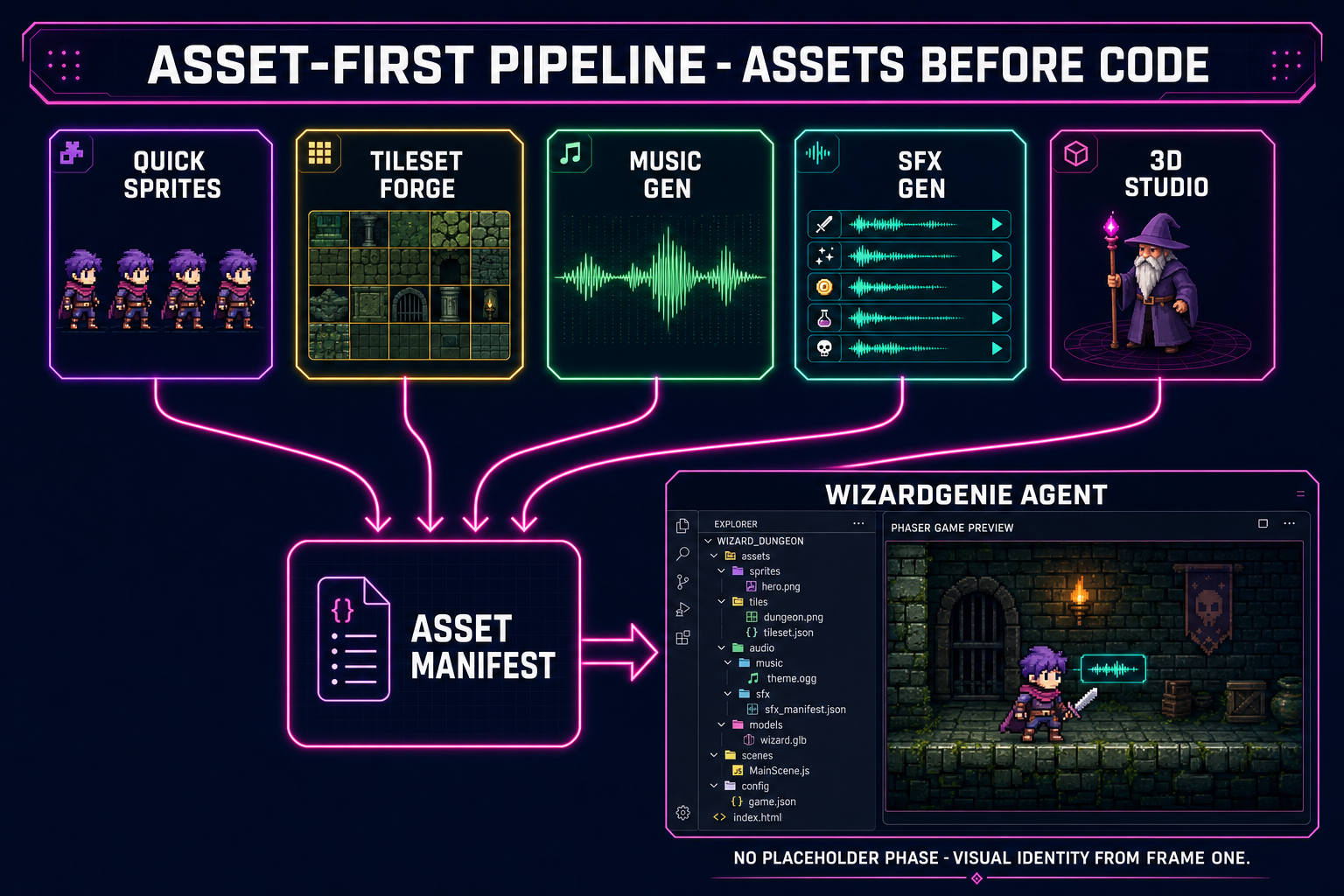
- Asset-first pipeline. Generate the sprites, the music, the SFX, and the 3D characters first; feed them to the agent as a manifest; let the agent wire the gameplay around finished assets. Best when you already know the visual identity you want and you do not want the agent inventing placeholder squares. Two to four hours of asset work, then a clean code session.
- Genre-template prompt pattern. Use a structured prompt that names the genre, the player verbs, the win condition, and the loss condition explicitly. Best when you want the agent to skip the “what kind of game is this” question and go straight to the mechanic implementation. Bypasses ten minutes of clarifying questions.
The four pipelines are not exclusive — most real projects start in pipeline 1, switch to pipeline 2 around iteration three, and pull in pipeline 3 once the visual identity locks in. The genre-template pattern (pipeline 4) is a prompt-engineering technique you can layer on top of any of the other three. The rest of this guide walks each one in order.
What “prompt to game AI” actually means in 2026
The phrase covers more ground than the marketing suggests. A prompt to game AI is not a single model that emits a finished game from a sentence; it is a coding agent that runs a multi-step loop — read the prompt, plan the file tree, write the code, run it, observe the output, fix the next bug, repeat — with you steering. The agent does the typing; you do the design taste, the bug spotting, and the “no, the jump should feel heavier” calls.
Every modern prompt-to-game AI system has the same three primitives under the hood. The first is a frontier-class language model that can reason about Phaser scene graphs, Three.js renderers, game loops, AABB colliders, frame-rate-independent movement, and the dozen other primitives that separate a working game from a static page. The second is a tool-use harness that lets the model call file-write, file-read, npm-install, run-the-dev-server, and read-the-console-output as actions rather than text. The third is the runtime — an actual browser tab where the game executes, so the agent can observe what the code did rather than guessing from what it wrote.
WizardGenie packages those three primitives into one editor. It runs in your browser at /wizard-genie/app with no install, ships a Windows desktop build with native filesystem access for longer projects, drives every leading coding model (Claude Opus 4.7, Claude Sonnet 4.6, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4 Pro, Kimi K2.5, Grok 4.2, MiniMax M2.7), and emits browser-playable games on Phaser 4 for 2D and Three.js r184 for 3D. The Sorceress asset suite (3D Studio, Quick Sprites, Music Gen, SFX Gen, Voxel Studio) is wired straight into the editor so generated assets land in the project tree without an export step. The model lineup and engine targets are verified against src/app/_home-v2/_data/tools.ts on May 12, 2026.
Pipeline 1 — The one-shot prompt-to-playable path
The fastest of the four pipelines. You write one paragraph, the agent writes one game, you click run. Best for “is this idea worth a real session” and for the first ten minutes of a game jam. The five steps:
- Open WizardGenie and start a new project. The editor at /wizard-genie/app opens a fresh project with a Phaser 4 scaffold by default. Pick “blank Phaser project” for 2D or “blank Three.js project” for 3D — the agent reads the scaffold and uses it as the starting point.
- Pick a model. The model picker in the top bar lists every coding model the project supports. For one-shot prompts, Claude Opus 4.7 or GPT-5.5 produce the cleanest first-draft scenes. The picker shows credit cost and the “trial tokens remaining” chip if you have not added your own API key yet.
- Write one paragraph. The prompt should include the genre, the player’s control verbs, the win condition, and the loss condition. Example: “A 2D top-down arena shooter where you move with WASD, aim with the mouse, shoot with left click. Enemies spawn from the edges and chase you. You die in three hits. Score goes up per kill. Wave count goes up every twenty kills.”
- Hit run. The agent emits the file tree, the dev server starts, the browser tab loads the scene. End-to-end on one-shot Claude Opus 4.7 runs is two to four minutes for a 2D scene, three to seven minutes for a Three.js scene with one rigged character.
- Iterate by talking. “The bullets are too fast.” “The enemy spawn rate is unforgiving.” “The score should be in the top-right.” The agent reads the running scene’s state, edits the relevant file, the dev server hot-reloads. This is the vibe-coding loop made tangible — design feedback at the speed of conversation. The vibe coding explainer walks the philosophy in detail.
What this pipeline ships: a scene that compiles, runs, and behaves roughly as described. What it does not ship: production-grade art, balanced difficulty, polished feel. The one-shot path is for “does this concept feel right”, not for “is this ready to ship”. The next pipeline is what you graduate to.
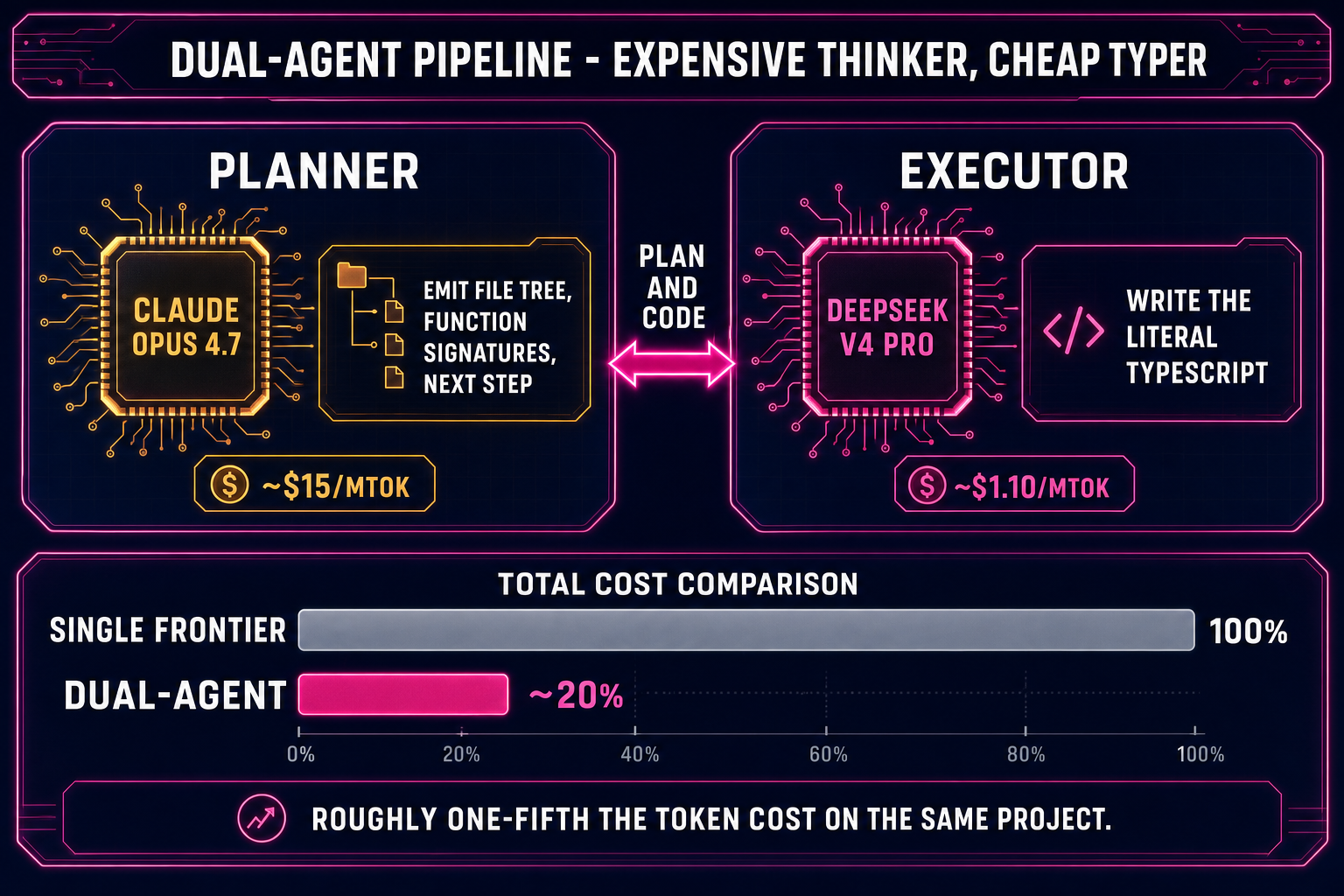
Pipeline 2 — The dual-agent Planner+Executor path
The cost-aware production pipeline. Two models share the work: a frontier reasoner (Planner) decides what to build and why; a cheaper fast model (Executor) writes the actual code. The Planner only emits high-level plans — file lists, function signatures, the next concrete step — and the Executor expands each step into the literal lines of TypeScript or JavaScript. The cost ratio is the point: a Planner+Executor pair using Claude Opus 4.7 + DeepSeek V4 Pro typically lands around one-fifth the token cost of running everything on Opus 4.7 alone, on the same project.
The economic logic is “expensive thinker, cheap typer”. Frontier models are billed per token of output, and game code is heavy on output tokens (file trees, boilerplate, scene definitions, asset wiring). The Planner emits a few hundred tokens of plan; the Executor emits the thousands of tokens of code. Most of the per-session cost lands on the Executor side, so swapping the Executor down to a budget model collapses the bill.
Acceptable Planners (top-tier reasoning, expensive but worth it on the planning side): Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, Grok 4.2. Acceptable Executors (genuinely cheap, fast, agent-ready, big context): DeepSeek V4 Pro, Kimi K2.5, MiniMax M2.7, Gemini 3.1 Flash, GPT-5.5 Mini. The pairing rule that matters: never put Sonnet, Opus, GPT-5.5, or Gemini Pro on the typing side — that erases roughly eighty percent of the cost advantage and is the most common way to misconfigure the pattern. The best AI model for coding write-up walks the model trade-offs in depth.
How to wire the pair inside WizardGenie: the model picker has a “dual-agent” toggle that exposes two slots — Planner and Executor — instead of one. Pick a top-tier reasoner in slot one (Opus 4.7 is a safe default) and a budget agent-ready model in slot two (DeepSeek V4 Pro is the workhorse). The agent loop now alternates: the Planner reads your prompt and the current project state, emits a plan; the Executor takes the plan and writes the files; the dev server reloads; you observe the result and reply. The session feels identical to single-model except the credit chip drains noticeably slower.