Searches for vibe coding with claude in 2026 split into two camps: devs who already pay for a Claude subscription and want to know how to point Anthropic’s models at a game project, and indies coming from cheaper agents who heard about Opus 4.8 in the May 28, 2026 release and want a sober field test before committing. This is that field test. We walk every Claude surface you can vibe-code in, name the model picks that actually fit a game-dev session, run the Planner + Executor math that drops cost to roughly one-fifth of solo-frontier billing, and finish with the browser-tab loop that wraps Claude alongside the four asset panels Claude itself cannot render. Every fact in this post was verified against the live source on June 6, 2026.

What “vibe coding with claude” actually means in 2026
Vibe coding is the workflow Andrej Karpathy named in February 2025 (per the Vibe coding Wikipedia entry and Simon Willison’s February 6, 2025 weblog post): describe intent in plain English, accept the diff sight unseen, run the build, watch the screen, react to what the screen shows. Vibe coding with Claude, then, is running Anthropic’s frontier models (Opus 4.8, Sonnet 4.6, or Haiku 4.5) in auto-edit mode where the agent applies edits without per-change confirmation, with the developer reading the running game instead of every line of the diff.
The Claude side of the loop has four real surfaces in 2026, and the model behavior is identical across all four because they hit the same API. What differs is the wrap: the Claude.ai chat app on the web, the Claude Code terminal CLI (currently v2.1.154 from May 28, 2026), the Claude API direct (BYOK billing per million tokens), and Claude embedded inside another editor like WizardGenie, the AI-native game engine at the heart of Sorceress. Picking the surface is the first decision; picking the model second; picking the posture third.
Two related posts on this site cover sibling angles: the claude vibe coding for games piece walks the brand-anchored framing, and the use Claude Code for vibe coding field test focuses specifically on the terminal CLI. This piece focuses on the practical “I have a Claude account, point me at a game project” angle — which surface, which model, which posture, which wrap.
The four Claude surfaces you can vibe-code in (and why the wrap matters)
Surface one is Claude.ai chat on the web. The chat tab is the simplest entry point: paste a brief, copy back the code, paste into your editor. The posture is “assisted” rather than vibe-coded because the chat surface does not apply diffs to your project. Useful for one-off snippets and architecture questions; the wrong tool for a 35-minute vibe loop because the manual paste-and-tab tax kills the “watch the screen” posture vibe coding wants.
Surface two is Claude Code, the agentic terminal CLI (per the CLI Wikipedia entry). It runs in any modern terminal, reads your project, executes shell commands, applies file edits as diffs, and ships Opus 4.8 as the default reasoning model in v2.1.154 (released May 28, 2026, with high effort by default and an /effort xhigh mode for the hardest tasks). The v2.1.154 release also introduced Dynamic Workflows, an orchestration primitive where Claude coordinates tens to hundreds of parallel sub-agents in the background. For a code-only artifact (a web app, a CLI tool, a backend service) the terminal is the cleanest wrap.
Surface three is the Anthropic API direct. BYOK billing per million tokens, no subscription wrap, useful when your project ships its own agent loop and the “wrap” is your own code. The rate card runs Opus 4.8 at $5 input / $25 output per million tokens, Sonnet 4.6 at $3 / $15, Haiku 4.5 at $1 / $5, with prompt caching cutting cached input by roughly 90 percent. Useful for custom integrations; not the right wrap for a vibe loop unless you have built one.
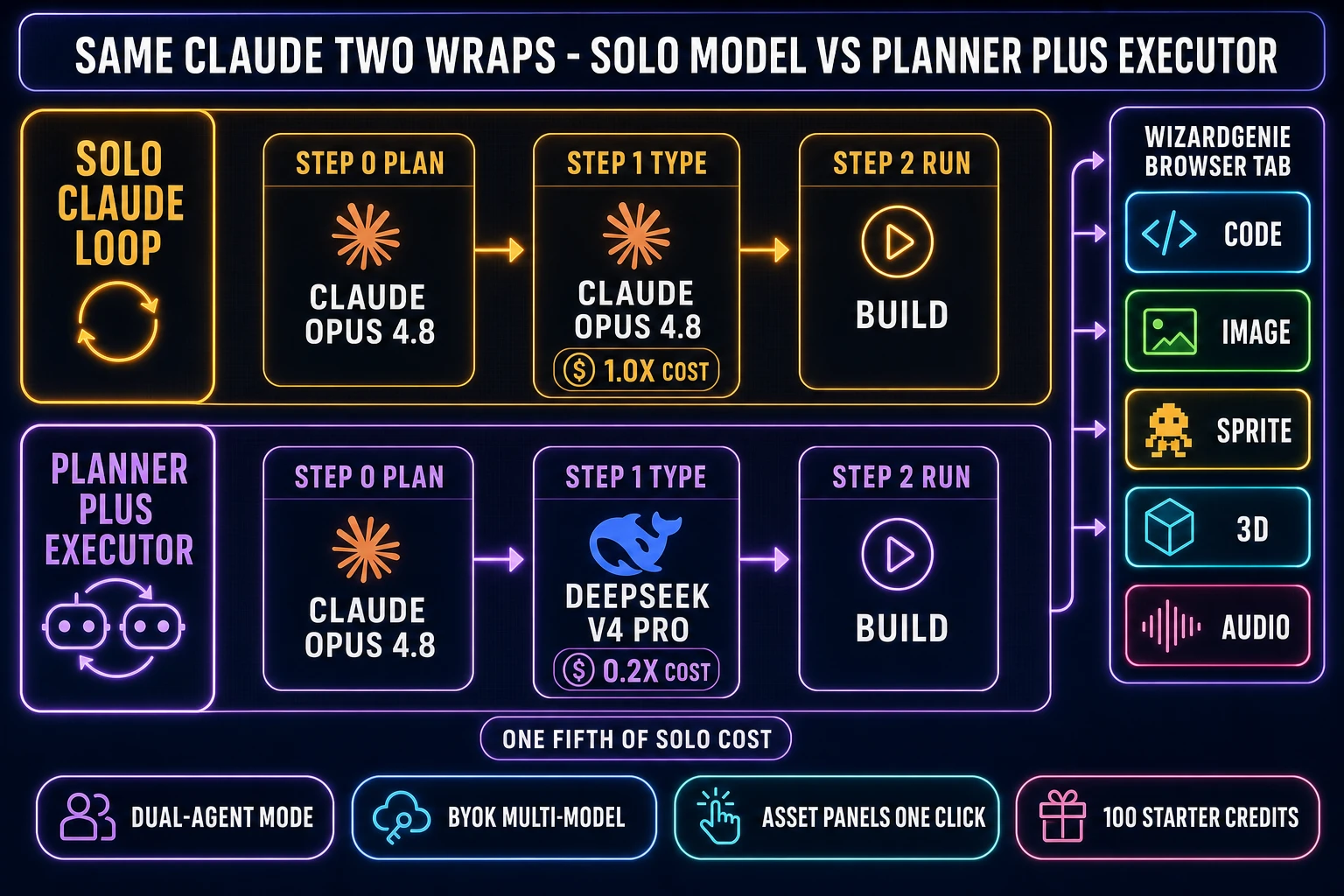
Surface four is Claude inside WizardGenie, the AI-native game engine at /wizard-genie/app. WizardGenie talks to the same Anthropic Claude API the other three surfaces talk to, so the model behavior is identical. The difference is the wrap: a multi-model picker (Claude is one of eight rails verified against src/app/_home-v2/_data/tools.ts on June 6, 2026), a Dual-agent Planner + Executor mode for the cost split, and the four asset tools (image, sprite, 3D, audio) in adjacent panels in the same browser tab. For a game project specifically, this is the wrap that closes the four-step asset wall every Claude vibe loop bounces off when it tries to ship a finished game.
Opus 4.8 vs Sonnet 4.6 vs Haiku 4.5: which Claude to pick for vibe coding with claude on games
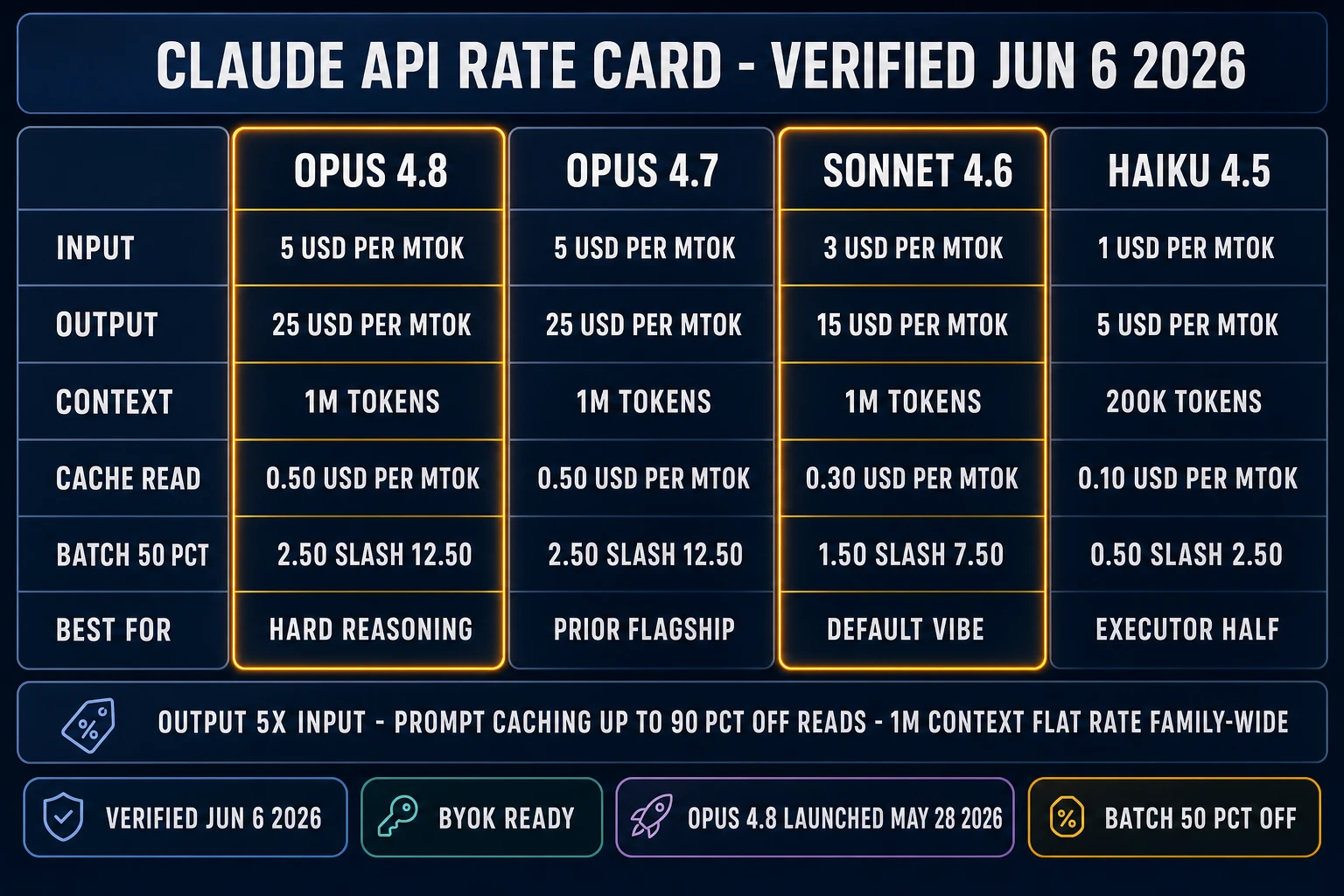
The model lineup that matters for vibe coding with Claude on a game project as of June 6, 2026: Opus 4.8 (current flagship, $5 input / $25 output per million tokens, 1M-token context window), Opus 4.7 (prior flagship, same price and context), Sonnet 4.6 ($3 / $15, 1M context), and Haiku 4.5 ($1 / $5, 200K context). Output tokens are 5x input across the family. Cache reads charge 10 percent of base input price. Batch API delivers a 50 percent discount across the board for non-time-sensitive workloads.
Sonnet 4.6 is the default vibe-coding model for a small to mid game project. It is fast, smart, and at $3 / $15 per million tokens it leaves enough budget for a long agent session. A typical 35-minute Phaser-platformer vibe session on Sonnet 4.6 lands around $1 to $3 of API-equivalent spend on a brand-new working directory. The model picker in WizardGenie defaults to it for exactly this reason: most game-dev vibe sessions are pattern-recognition work (Phaser arcade physics, three-js boilerplate, Godot GDScript idioms) where Sonnet’s training distribution already knows the right answer.
Opus 4.8 is the upgrade pick for hard-reasoning work — a tricky multiplayer netcode bug, a custom shader pipeline, an architecture choice between two physics models, a refactor that crosses six files. Opus is roughly 1.7x the per-token cost of Sonnet for the same workflow, but it catches more edge cases on the first try and reduces the paste-the-error follow-ups in a vibe loop. The May 28, 2026 release made Opus 4.8 default to high effort and added an /effort xhigh mode for the hardest tasks; the Fast Mode on Opus 4.8 is now available at 2x the standard rate for 2.5x the speed, which is a strict improvement on the prior Opus 4.7 baseline at the same effort level.
Haiku 4.5 is the executor pick for the typist half of a Planner + Executor split. At $1 / $5 per million tokens, Haiku is cheap enough that running it on the bulk of an agentic session keeps the rate card honest. The catch: Haiku stays at the 200K-token context window where Opus and Sonnet both ship 1M; for a long-context game-dev session, fall back to DeepSeek V4 Pro or Kimi K2.5 as the executor instead (see the Planner + Executor section below). For more on the full eight-rail picker logic, the longer read at best AI model for coding covers it.
The vibe coding posture with Claude: accept the diff, run the build, watch the screen
The posture is what distinguishes vibe coding from pair programming. Both run on the same Claude API; the human decides which posture is active. Pair programming with Claude is the propose-then-confirm flow with line-by-line diff review — the dev reads every change before accepting it. Vibe coding with Claude is the opposite: auto-edit mode, accept the diff sight unseen, run the build, look at the screen, react to what the screen shows. The dev’s eyes are the only validator; the dev never line-edits the agent’s output.
For a game project specifically, the practical vibe loop with Claude is: open a one-paragraph brief (“build a side-scrolling Phaser 4 platformer in TypeScript with double-jump, three coin pickups, and patrolling slime enemies”), click accept on diff after diff, watch the build, paste back any error, and react to the screen. The loop produces gameplay code (movement, collision, scoring, scene transitions) reliably; in a typical 35-minute Opus 4.8 session it ships a working vite + Phaser 4 + TypeScript project that builds and runs on the first npm run dev, with correct double-jump logic, a score HUD using Phaser BitmapText, and an enemy patrol loop. The two times the build throws an error, Claude recovers in one paste-back of the stack trace.
The longer write-up at vibe coding meaning for indie game devs walks the posture argument in more depth, and the is Claude Code vibe coding piece argues the same posture distinction on the CLI surface specifically. The short version: the binary is the same, the posture is the choice. Vibe coding with Claude means picking the loose posture on purpose.
Where vibe coding with Claude shines (gameplay code) and where it stops (the four-step asset wall)
The gameplay-code half of a vibe session with Claude is the success story. The asset half is where the wall sits. A finished game is gameplay code plus a sprite sheet (per the Sprite computer graphics Wikipedia entry, sprites are rasterized images that get composited at runtime), plus a 3D mesh when the game is 3D (per the glTF 2.0 specification at Khronos, meshes are vertex / index buffers with material maps), plus a rigged skeleton for animation (per the Skeletal animation Wikipedia entry), plus music, plus sound effects, plus voice.
Claude, as a frontier text and code model (per the Large language model Wikipedia entry), can write the gameplay code that references those assets. It cannot render the pixels for the sprite, it cannot extrude the 3D mesh, it cannot rig the skeleton, and it cannot synthesize the WAV file. Asking Claude to do those steps anyway returns a Pillow Python snippet that runs against a path that does not exist, a bullet list of frame indices into a tileset that also does not exist, an apology and a suggestion to record the chime on a phone, or a 256-line JSON stub of tile indices into a tileset that also does not exist. None of that is a Claude failure — frontier coding LLMs are trained on text, not on pixel-art conventions, palette quantization, mocap retargeting, or drum patterns.
The vibe-coding posture meets the asset wall the same way regardless of which Claude surface you point at the project. The posture is “accept what lands.” What lands from a code-only model is gameplay code plus stubs. The fix is not to switch agents; it is to feed real assets into the same project from a tool that actually generates pixels and audio. That is the entire reason the WizardGenie wrap matters for game projects in a way it does not matter for web apps.