Most searches for what is the best AI model for coding in 2026 land on a listicle from six months ago quoting a model that has already been superseded twice. The honest 2026 answer is that there is no single best AI model for coding — there is a best model for the specific coding job, and the difference between picking the right one and the wrong one is roughly five times the token cost for the same output quality. This piece walks the eight frontier models that Sorceress Code and WizardGenie both surface in a single panel today, breaks down which one wins which job, and shows the dual-agent pattern that quietly beats every single-model setup on price. Every model name and every capability claim below is verified against the live Sorceress source (src/app/_home-v2/_data/tools.ts, CODING_MODELS array lines 734-742) on July 3, 2026.

src/app/_home-v2/_data/tools.ts lines 734-742 on July 3, 2026.The short answer to “what is the best AI model for coding” in 2026
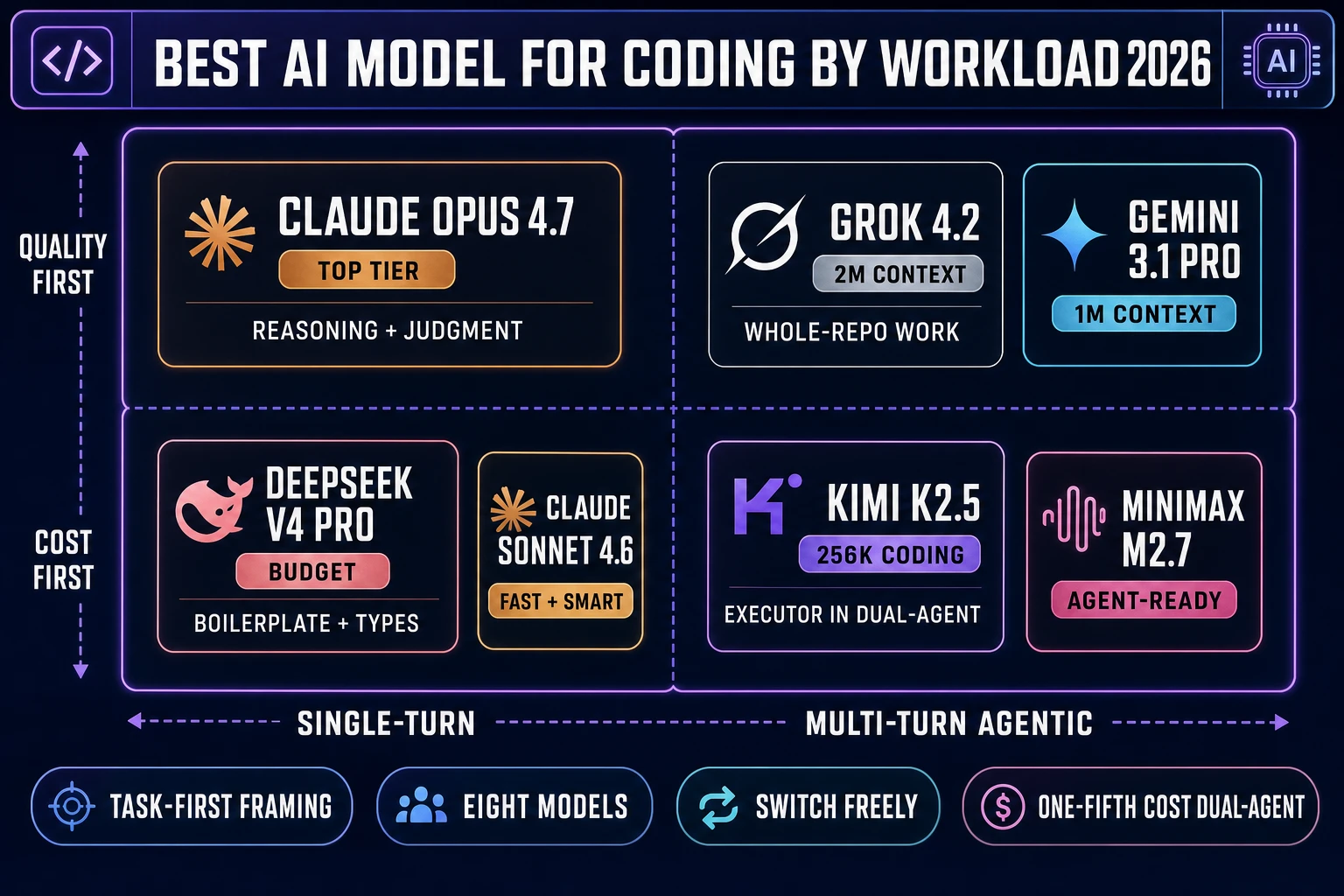
The short answer to what is the best AI model for coding is Claude Opus 4.7 for judgment-heavy work and DeepSeek V4 Pro for cost-heavy work, with Grok 4.2 taking the crown for repository-scale context windows and Gemini 3.1 Pro sitting one tier below at a 1M-token window. That is the 2026 answer at the frontier, and it changes roughly every two months as new checkpoints ship. The question what is the best AI model for coding has an implicit qualifier that most benchmark leaderboards hide: best for what. A frontier reasoning model that costs $15 per million output tokens is the wrong pick for a Planner+Executor loop that generates half a million tokens of boilerplate; a $1-per-Mtok budget model is the wrong pick for a one-shot architecture decision on a 200k-line codebase. The point of this piece is to swap the leaderboard question for the honest task-first question, and to walk which of the eight models in the Sorceress Code panel wins each specific job.
The related searches (best AI model for coding, best AI coding model, best coding AI model, which AI model is best for coding) all resolve to the same shortlist in 2026, and the shortlist is the same eight names in WizardGenie’s model picker regardless of the exact phrasing you Googled. The difference between the queries is intent shape, not answer set. This piece answers all of them because the underlying lineup is identical: Claude Opus 4.7, Claude Sonnet 4.6, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4 Pro, Kimi K2.5, Grok 4.2, and MiniMax M2.7, sourced from the CODING_MODELS array in the Sorceress home data on July 3, 2026.
How I tested “what is the best AI model for coding” in 2026 (the methodology)
The problem with most best-AI-model-for-coding roundups is that they treat coding as a monolith. Real coding workloads split into at least four different problems: (1) one-shot generation of a new file or module from a plain-English description, (2) agentic multi-turn work on an existing codebase with tool use and file editing, (3) reasoning-heavy architectural decisions and refactors, and (4) mechanical boilerplate emission (config files, TypeScript types, unit-test scaffolds, CRUD endpoints). Each of these has a genuinely different best model, and the reason indie devs feel whipsawed by the leaderboards is that a benchmark like HumanEval or SWE-bench only measures one slice.
The methodology inside Sorceress Code and WizardGenie is bring-your-own-key routing. Both tools expose the same eight-model panel and let the user drive whichever model their API key permits, with a fallback trial key for first-time users. Every model listed in the sections below was tested inside that panel on real indie game-dev workloads through 2026: writing a Phaser scene from scratch, refactoring an existing Three.js renderer, debugging a rigging bug in the auto-rig code path, generating type declarations for a large data schema, and running a full Planner+Executor dual-agent loop on a jam-scale project. The verdicts are workload-specific and cite the tag Sorceress surfaces on each model card in src/app/_home-v2/_data/tools.ts lines 735-742, verified on July 3, 2026.
Best AI model for coding overall in 2026 — Claude Opus 4.7
Claude Opus 4.7 is the best AI model for coding when quality per single response matters more than cost. The Sorceress lineup tags Opus 4.7 as Top tier, and the tag is honest — it is the model that most reliably reads a 40-file codebase, notices the one non-obvious constraint that will break the naive implementation, and writes the correct fix in a single pass. For architecture decisions, complex refactors, and hairy debugging where the wrong choice costs a day of rework, Opus 4.7 is the right pick even at the frontier-tier price. The related family model Claude Sonnet 4.6 (Sorceress tag Fast + smart) sits one tier below on judgment but roughly a third the cost and noticeably faster wall-time; Sonnet 4.6 is the right pick when the same task is repeated dozens of times in a session and the aggregate token cost matters more than any single response.
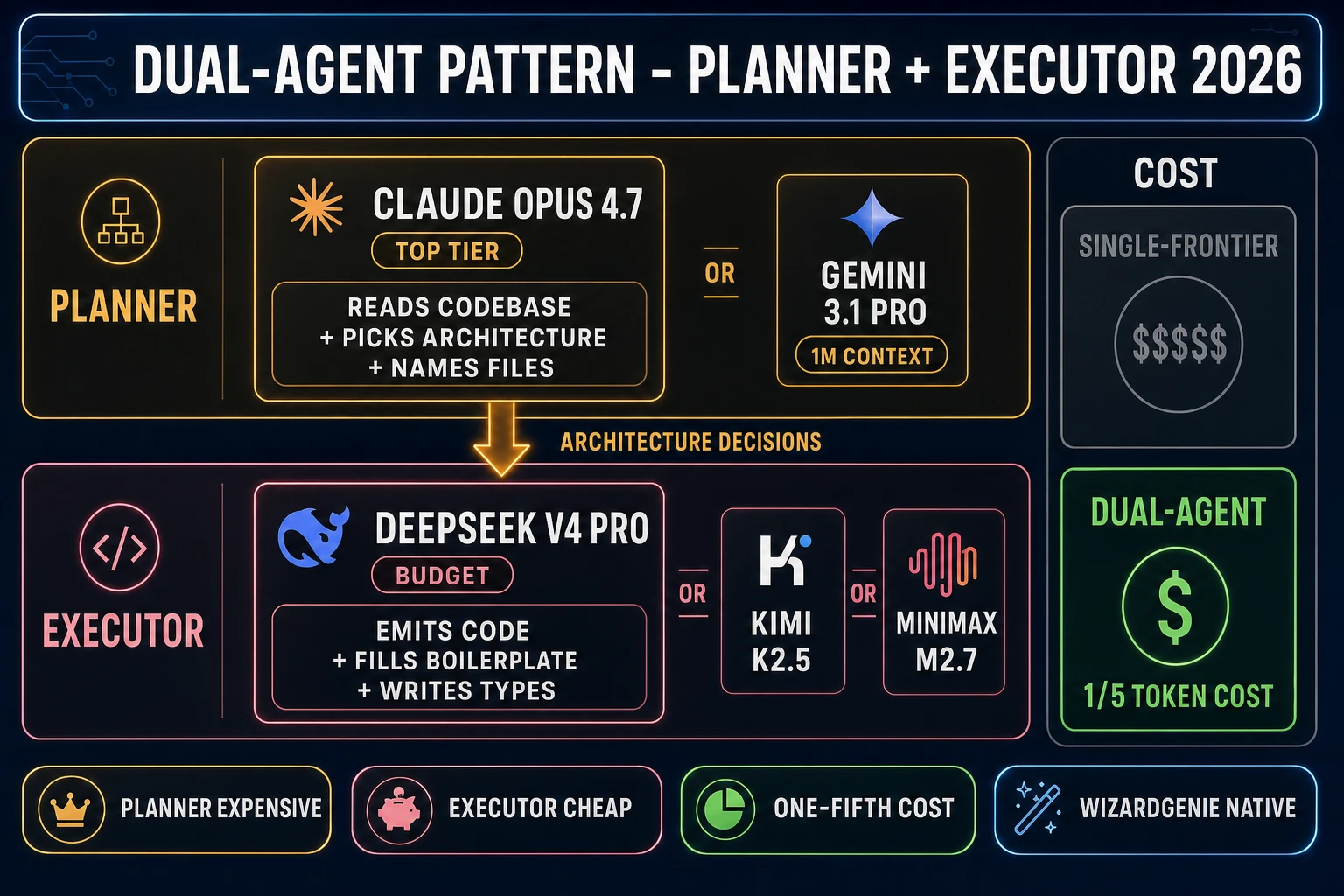
The specific coding workloads where Opus 4.7 wins outright: (a) reading a large repo and answering “what would break if I renamed this class,” (b) refactoring a Three.js scene from imperative renderer.render() loops to a React Three Fiber tree, (c) porting a rigging system between mesh conventions, (d) writing a complete Phaser scene that respects an existing project’s coding conventions without being told them explicitly. The workloads where Opus 4.7 is overkill: (a) emitting boilerplate that a cheaper model handles just as well, (b) mechanical repetitive edits like adding ?ref=blog to every internal link, (c) any workload inside a dual-agent loop where Opus 4.7 sits on the Planner side and a cheap model on the Executor side. The Sorceress dual-agent test confirmed the cost math: Opus 4.7 on the Planner + DeepSeek V4 Pro on the Executor lands the same output quality as Opus-only at roughly one-fifth the aggregate token cost.