Searches for the best local ai model for coding in 2026 split into two camps: privacy-first developers who want to run their coding agent entirely offline on hardware they own, and budget-first developers who want to skip per-token API bills by buying one GPU and amortizing the cost across an unlimited number of sessions. Both camps land on the same handful of open-weight models and the same hardware-tier matrix. This post walks the matrix end-to-end, names the genuine 2026 winners at each VRAM tier with verified HumanEval and SWE-bench Verified scores, runs the actual install path on Ollama and LM Studio, exposes where local still trails frontier cloud, and finishes with the no-GPU alternative that drives the same caliber of coding agent from a browser tab. Every benchmark and version in this post was verified against the live source on June 7, 2026.

What “best local AI model for coding” actually means in 2026
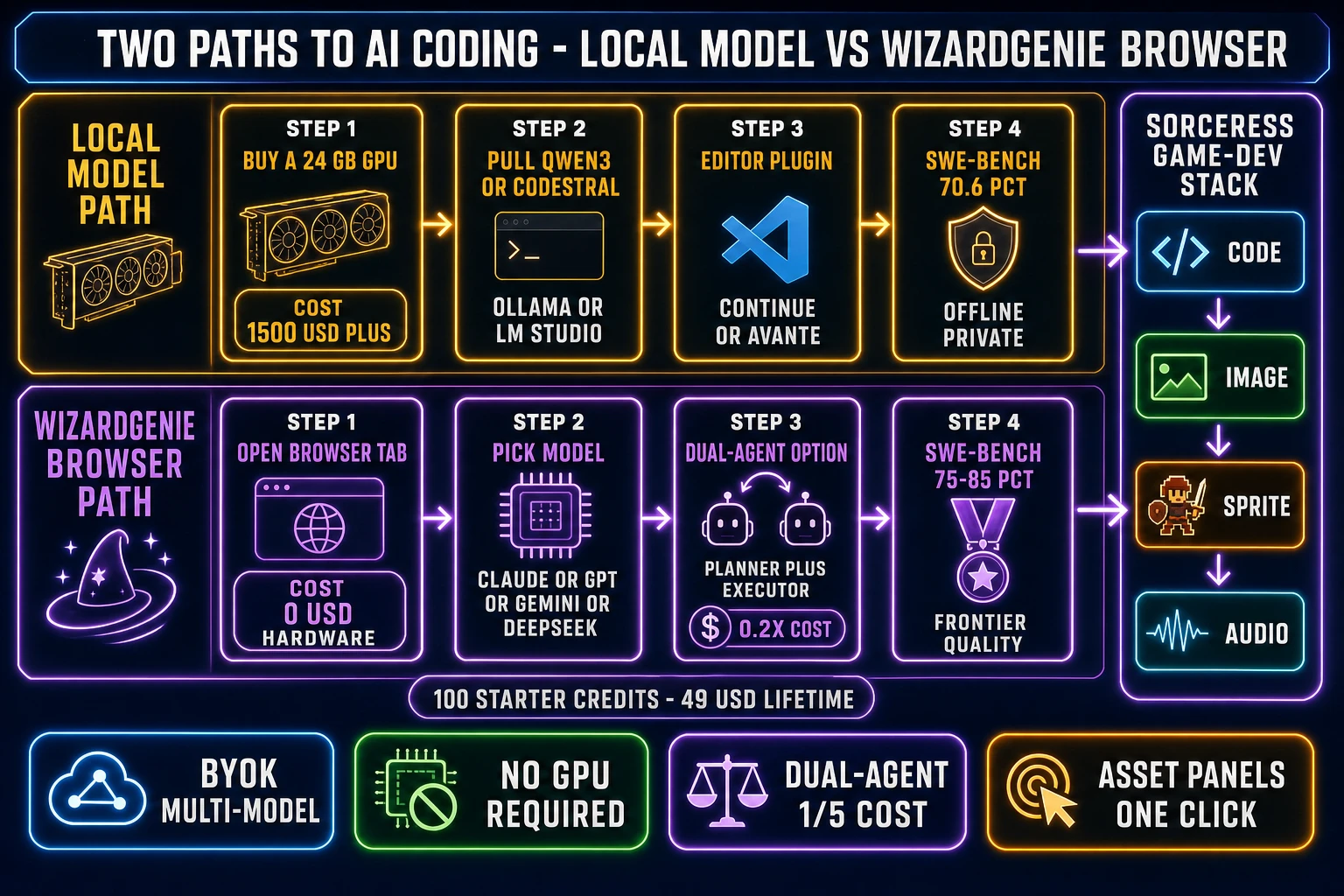
The phrase local in “best local AI model for coding” has a strict technical meaning: the model weights live on the developer’s own hardware, inference runs against the developer’s own GPU or unified-memory Apple Silicon, and no token ever leaves the machine. That definition rules out any hosted inference (Together AI, Groq, Fireworks, vendor APIs), even when those services charge less than a power bill. The audience for the local-only constraint is split roughly in three: developers under enterprise privacy mandates, developers in regions with patchy internet or strict export controls, and developers who would rather amortize a one-time $1,500–$5,000 GPU spend across unlimited prompts than ride the API meter.
The 2026 local-LLM landscape changed substantially from 2025. The pre-2025 generation (Code Llama 70B, the original Qwen 2.5 Coder, the original Codestral 22B) gave way to a Mixture-of-Experts wave (per the Mixture of experts Wikipedia entry) that ships frontier-class total parameter counts while activating only a fraction during inference. The flagship of that wave for coding is Qwen3-Coder-Next, an 80B-total / 3B-active MoE released by Alibaba in February 2026 (per the official Qwen3-Coder Technical Report on arXiv as 2603.00729). The active-parameter trick is what lets it run interactively on a single 24 GB consumer GPU while matching coding scores from dense models 10 to 20 times larger.
The benchmark vocabulary also shifted. HumanEval (per the HumanEval Wikipedia entry) measures whether a model writes a correct standalone function given a docstring and a few unit tests — useful for snapshot quality, less useful for real engineering work. SWE-bench Verified (per the original SWE-bench paper from Princeton NLP) measures whether a model can resolve actual GitHub issues in production codebases, including multi-file edits and test-suite execution. The 2026 consensus across r/LocalLLaMA and the major benchmark trackers is to weight SWE-bench Verified more heavily than HumanEval when ranking the best local AI model for coding, because the SWE-bench setup mirrors what an agentic editor actually does on a real project.
The hardware reality: 12 GB / 16 GB / 24 GB / 48 GB+ VRAM tiers
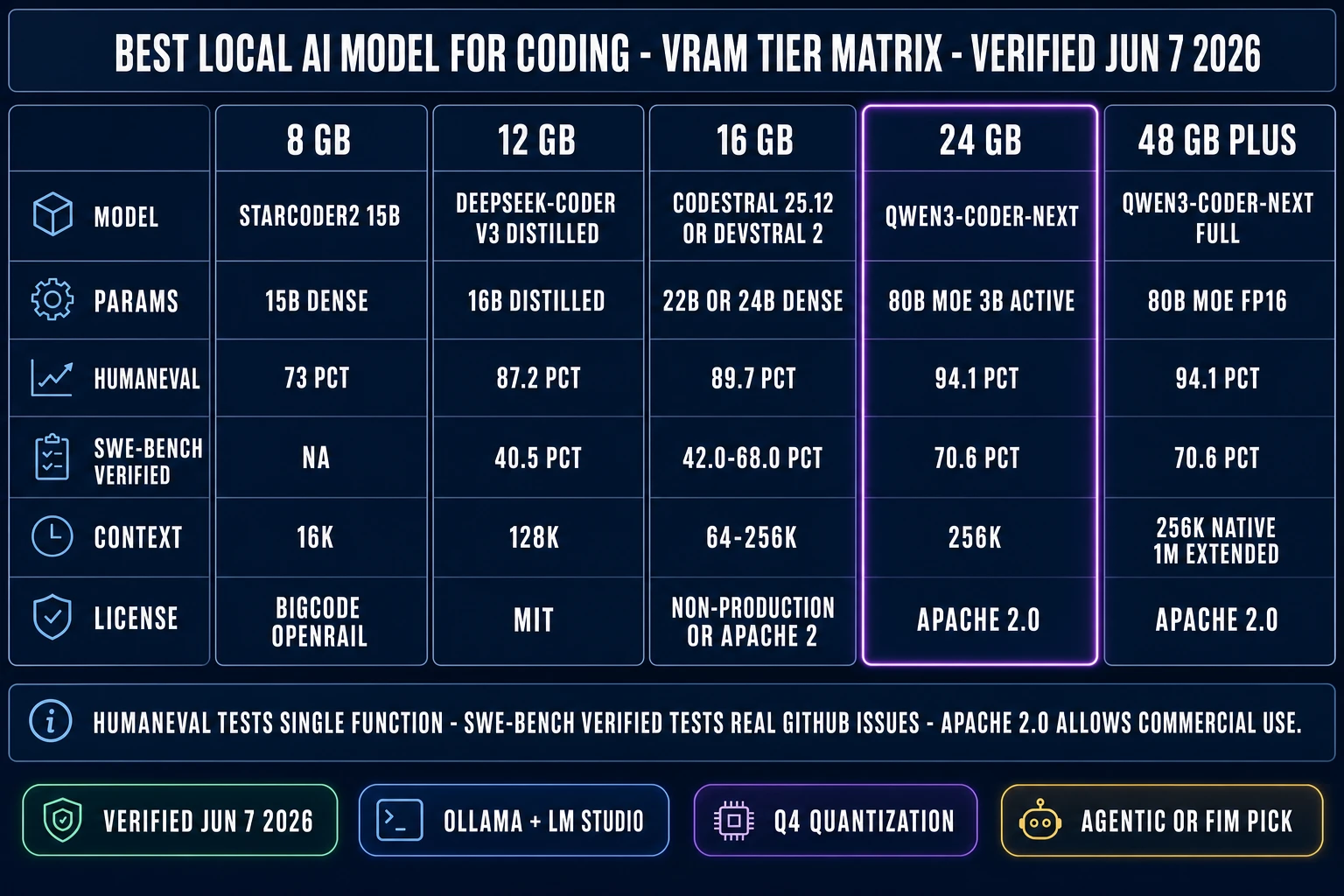
Choosing the best local AI model for coding starts with the GPU on the desk, not the leaderboard. The four hardware tiers worth knowing in 2026, verified against benchmarks published by AI Hub, Local AI Master, and the Qwen3-Coder-Next Technical Report on June 7, 2026:
- 8 GB VRAM (RTX 4060, RTX 3060 8 GB, RTX 4060 Mobile). Runs Qwen 3 8B or StarCoder2 15B at Q4 quantization (per the Quantization Wikipedia entry). HumanEval lands around 73–78%. Multi-file agentic loops become unreliable because the 16K context window on StarCoder2 cannot hold a typical small game project, and the active-parameter count is too low for hard reasoning.
- 12 GB VRAM (RTX 4070 Ti 12 GB, RTX 3060 12 GB, RTX 4070 Mobile). Runs DeepSeek-Coder V3 Distilled at 16B parameters with 87.2% HumanEval and 40.5% SWE-bench Verified. The 128K context window is enough for most single-file edits and short multi-file refactors, and the distilled architecture preserves most of the parent model’s reasoning quality.
- 16 GB VRAM (RTX 4070 Ti Super, RTX 4080 Mobile, RTX 4060 Ti 16 GB). Two viable choices. Codestral 25.12 (22B dense, 89.7% HumanEval, 42.0% SWE-bench, 95.3% HumanEval-FIM autocomplete — the SOTA fill-in-the-middle score). Devstral Small 2 (24B, 68% SWE-bench Verified per one source and 72.2% per another, 256K context, Apache 2.0). The pick splits by use case — Codestral for inline autocomplete, Devstral for agentic multi-file editing.
- 24 GB VRAM (RTX 4090, RTX 3090, A6000 used). The recommended sweet spot. Runs Qwen3-Coder-Next at full Q4 quantization with 94.1% HumanEval, 70.6% SWE-bench Verified (71.3% with the OpenHands scaffold), and a 256K-token context window. Also runs DeepSeek V3.2 with offload (93.4% HumanEval, 56.1% SWE-bench, industry-leading LiveCodeBench algorithmic score). The single-RTX-4090 setup is the consensus 2026 best local AI model for coding rig at the time of writing.
- 48 GB+ VRAM (A6000 Ada, dual 4090, H100). Runs the Qwen3-Coder-Next GGUF at 52 GB Q4_K_M without quantization-tier compromises, plus the largest context windows. Also opens the door to Kimi K2.6 (MoE, 32B active, scoring 87/100 on community real-world benchmarks) and Llama 4 Scout (109B / 17B active, 10M-token context, the longest context window in the open-weight world).
The Mac variant of the matrix is different because Apple Silicon’s unified memory architecture trades raw bandwidth for being able to address the full model in memory without VRAM partitioning. On a 32 GB M-series Mac, Devstral Small 2 or a Q4 Qwen3-Coder is the best pick. On a 96 GB+ Mac Studio or M-series Pro tower, Kimi K2.6 and DeepSeek V3.2 become viable in unified memory without the multi-GPU NVLink overhead a Windows or Linux box would need at the same parameter count.
The open-weight coding models worth testing (verified 2026)
Qwen3-Coder-Next (Alibaba) is the overall best local AI model for coding in 2026. The 80B-total / 3B-active MoE design, the Apache 2.0 license, the 256K-token context window, and the 70.6% SWE-bench Verified score (71.3% with OpenHands scaffold) make it the consensus pick across r/LocalLLaMA and every 2026 ranking that weights real-engineering benchmarks. The full GGUF Q4_K_M package is about 52 GB on disk; the Q4 quantization runs comfortably on 24 GB VRAM with room for a 60K-token working context. The flagship sibling Qwen3-Coder-480B-A35B-Instruct (480B total, 35B active) rivals Claude Sonnet on agentic coding benchmarks but requires a multi-GPU rig and is rarely the right pick for a single-developer workstation.
Devstral Small 2 (Mistral) is the agentic specialist on consumer GPUs. 24B parameters, 16 GB VRAM, 256K context, Apache 2.0 license, and an SWE-bench Verified score in the 68–72% range depending on the scaffold used. It edges Codestral on multi-file agentic loops and trails Qwen3-Coder-Next slightly on single-function correctness, but the cost difference (16 GB vs 24 GB hardware) tips the value calculus toward Devstral for the majority of 16 GB-tier developers.
Codestral 25.12 (Mistral) is the autocomplete king. 22B dense, 16 GB VRAM at Q4, 64K context, HumanEval 89.7%, SWE-bench Verified 42.0%, and the highest HumanEval-FIM score (95.3%) of any model — including frontier cloud models. The fill-in-the-middle metric is the right benchmark for inline IDE autocomplete because it tests exactly what an editor needs: predict the code that goes between the cursor’s prefix and suffix. The catch: Mistral’s Non-Production License restricts commercial use, so a working game studio cannot ship a product trained on Codestral’s output without a paid license — an Apache 2.0 alternative is required for that case.
DeepSeek V3.2 (and the imminent V4 Flash) is the algorithmic-coding leader on competitive programming benchmarks. The full 671B (37B active) model scores 93.4% HumanEval and 56.1% SWE-bench Verified, but pulls ahead on LiveCodeBench — a benchmark built from competitive-programming problems collected after the model’s training cutoff, which makes it harder to game. The 24 GB tier runs DeepSeek V3.2 with offload (slower than Qwen3-Coder-Next, comparable quality on most tasks, better on math-heavy and algorithmic work). The distilled 16B variant covers the 12 GB tier.
StarCoder2 15B (BigCode collaboration) is the 8 GB-tier pick and the recommended fine-tuning base for shops building custom in-house coding models. 16K context, ~73% HumanEval, no SWE-bench Verified score published, but the BigCode OpenRAIL-M license is the most commercially permissive in the open-weight coding-model world. For most 2026 sessions on hardware that can run a larger tier, StarCoder2 is the fallback rather than the destination.
Two more models are worth naming for completeness. Llama 4 Scout (Meta) at 109B / 17B active offers a 10M-token context window — the longest in the open-weight world — useful for one-shot whole-codebase reads, but 47.3% SWE-bench Verified puts it behind Qwen3-Coder-Next on agentic loops. Gemma 4 26B A4B (Google) at 14 GB VRAM and 84.9% HumanEval / 38.6% SWE-bench Verified is competent but rarely the best pick at its tier.
The best local AI model for coding by use case (agentic vs autocomplete vs algorithmic)
The single biggest mistake in picking the best local AI model for coding is choosing by leaderboard rank instead of by use case. The three use cases that matter on a 2026 developer workstation map to three different model picks:
- Agentic multi-file editing — the “accept the diff, run the build, watch the screen” loop where the model edits multiple files, runs commands, reads test output, and iterates. Pick Qwen3-Coder-Next at 24 GB or Devstral Small 2 at 16 GB. Both ship 256K context (large enough for a typical small-to-mid game project to live in working memory), agentic post-training, and tool-calling discipline. Avoid Codestral 25.12 for this use case — the 64K context window runs out fast on a real codebase.
- Inline IDE autocomplete — the fill-in-the-middle predictions a VS Code or Neovim plugin shows ghost-text-style as the cursor moves. Pick Codestral 25.12. The 95.3% HumanEval-FIM score is the SOTA across all models, open or closed, and the low-latency 22B dense architecture suits the high-frequency request rate of inline completion.
- Algorithmic and math-heavy code — competitive programming, dynamic programming, graph algorithms, custom shader math, physics simulation kernels. Pick DeepSeek V3.2 if you have 24 GB or DeepSeek-Coder V3 Distilled if you have 12 GB. The DeepSeek training mix and LiveCodeBench performance translate to better first-attempt correctness on the kind of code where a single off-by-one breaks everything.
The hybrid pattern that wins on a 2026 indie dev box: install Codestral 25.12 for inline autocomplete (fast, private, instant ghost-text), and install Qwen3-Coder-Next for agentic sessions in a separate editor mode (slower, multi-file, runs the build). Two models, two VRAM costs — both fit on a single 24 GB GPU because the agentic model is only loaded when the agentic session is active.