
Image to 3D model conversion is the single biggest unlock in indie game-dev pipelines right now. One AI-generated character portrait, one click, and you have a textured 3D mesh you can rig, animate, and drop into Unity, Unreal, Godot, or Three.js. No turntable photography, no Blender sculpting, no week of weight-painting. This is what the 2026 image-to-3D pipeline actually looks like end-to-end.
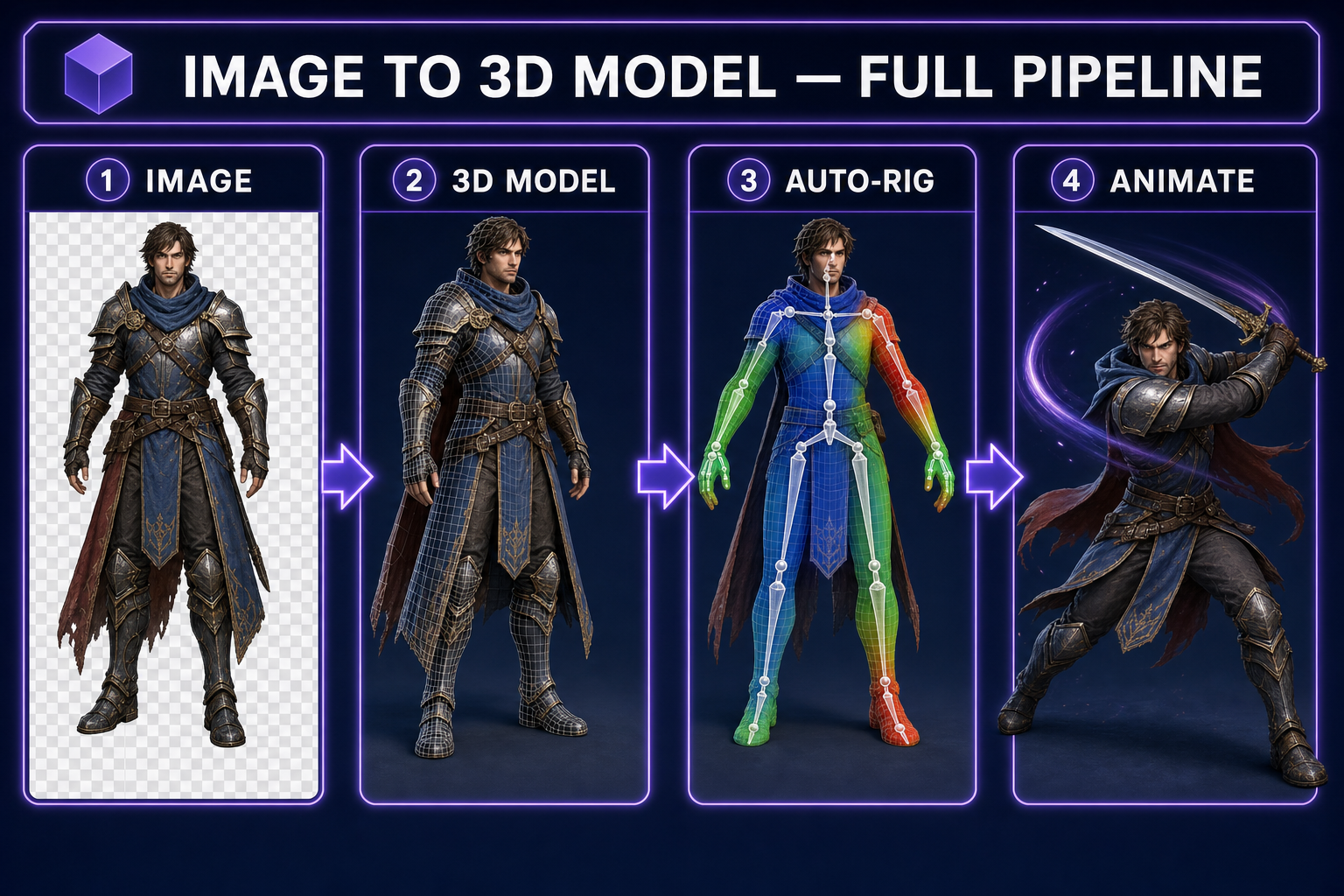
Image to 3D model in 2026
- Modern image-to-3D models reconstruct a fully textured 3D mesh from a single 2D image — no multi-angle photogrammetry required.
- The output (mesh + texture + UVs) is the input for the next two steps: auto-rigging and text-to-animation.
- End-to-end: one prompt → playable rigged 3D character in 3–8 minutes.
- Sorceress 3D Studio chains the whole pipeline on one surface: generate, lift to 3D, auto-rig, weight-paint, animate, export to FBX, GLB, or GLTF.
What “image to 3D” actually means in 2026 (and what it doesn’t)
Two different technologies share the name “image to 3D” and they are not the same thing. Knowing which one your tool runs determines what kind of asset you get.
- Photogrammetry takes many photos of the same physical object from different angles, finds matching feature points, and triangulates a point cloud. The output is geometrically accurate to the real object but typically noisy, hole-ridden, and badly UV-mapped. This is what apps like RealityCapture and Polycam do. It needs ten or more photos and gives you a static prop. Good for scanning real-world reference; bad for clean game assets.
- Single-image neural reconstruction uses a generative model to invent the back of a character based on a single front-facing image. The output is geometrically plausible rather than measured-accurate, but it’s clean, watertight, and ready for rigging. This is what 3D Studio runs and what most game-dev pipelines now use.
For indie game dev the choice is obvious: you don’t have the back of your character to photograph because you just generated it from a prompt thirty seconds ago. Single-image neural reconstruction is the only thing that works at the front of the pipeline.

The Sorceress 3D Studio pipeline (the four-step chain)
Every step of the image-to-3D pipeline lives in 3D Studio. You don’t move between tools, upload exports, or babysit a render queue. The four steps:
- Generate the source image. Prompt a character in any of the seven image models in AI Image Gen — the same workflow we covered in our character-generator guide. Pick a strong front-facing portrait. This will become the front face of the 3D model.
- Lift to 3D. One click. The image-to-3D model produces a fully textured mesh — geometry, UV-mapped texture, normals — typically in 30–90 seconds. Output is a clean GLB with proper alpha and PBR-friendly materials.
- Auto-rig. Identify the character’s silhouette as humanoid (or quadruped), drop a skeleton in, run automatic weight painting to attach the mesh to the bones. Refinable: you can tweak weights manually if a deformation is off, but for most jam-scale work the auto-rig ships clean.
- Animate (text-to-animation). Describe what the character should do in plain English (“wave hello”, “draw sword and slash”, “victory pose”). The model produces a keyframe animation on the rig you just built. Stack multiple animations on the same character: idle, walk, run, attack, death.
End-to-end on a humanoid character: 3 to 8 minutes from prompt to fully rigged, animated, exportable 3D character.
From single image to textured 3D model (what the model is actually doing)
The technical details are worth understanding because they tell you when the output will be reliable and when it’ll need cleanup.
- Geometry generation. The model uses a learned 3D prior — typically a triplane or volumetric representation distilled from a large dataset of paired image-to-3D examples — to predict the shape of the character behind what’s visible in the input. For a clean front-facing reference, this is reliable. For an oblique-angle source, the back of the character is less reliable because the model has less to work with.
- Texture projection. The texture from the input image is projected onto the front of the mesh. For the back, the model either inpaints plausible texture (fast, sometimes blurry) or generates a new texture using the same model that made the geometry (slower, sharper). Quality varies by model — high-end image-to-3D models in 2026 produce textures sharp enough to ship without retouching.
- UV mapping. Modern image-to-3D models output a clean UV layout — usually a single UV island for the body. Hand-editable in Blender if you need to optimize for a specific texel density target.
The practical takeaway: if your reference image is a clean, front-facing, full-body shot, the resulting 3D model is usually production-ready. If your reference is partial (just the upper body, oblique angle, occluded), expect to do some manual cleanup or regenerate from a stronger source.



