Type which AI model is best for coding into Google in 2026 and the first page is a wall of leaderboards ranking eight frontier models on synthetic benchmarks — HumanEval, SWE-bench, LiveCodeBench, the usual suspects. The leaderboards are real but they answer the wrong question for an indie game dev. The right question is not which model wins the benchmark; it is which model do I open when I sit down to write the goblin AI on a Tuesday afternoon. The honest answer is that the eight models in the WizardGenie coding picker each have a shape that fits a different slice of the indie game dev workflow. This piece is the decision tree, model by model, against the live lineup verified June 13, 2026 in src/app/_home-v2/_data/tools.ts.

What “best AI model for coding” actually means for indie game dev in 2026
Most coding-model leaderboards measure one thing: the percent of a benchmark problem set the model can solve unaided. That number is genuinely useful for an academic comparison and genuinely misleading for an indie game dev. Game dev coding is not a benchmark problem set. It is a long sequence of small surgical edits across a real codebase that already exists, interleaved with occasional one-shot prompts that scaffold a whole new system. The model that wins HumanEval may or may not be the model that handles the long sequence at the right cost.
The honest question an indie game dev should ask is not which AI model is best for coding in the abstract. It is a stack of four narrower questions: which model produces the cleanest one-shot scaffold when I start a new Phaser project from a single prompt; which model keeps my flow going through hundreds of small surgical edits across the next two weeks; which model can hold my whole repo in context when I need to refactor an entire system at once; and which model should type the actual tokens when an expensive planner is reviewing the diffs. Each of those four questions has a different right answer in the 2026 model landscape. The leaderboard answers none of them in isolation.
The rest of this piece walks each of those four questions against the eight-model lineup in WizardGenie and the lower-level Sorceress Code chat-and-diff interface. The leaderboard sister post at Best AI Model for Coding (We Tested All 8 in WizardGenie) covers the benchmark-style comparison; this post is the decision tree the leaderboard does not give you.
The eight frontier coding models in WizardGenie (June 13, 2026 live lineup)
Verified June 13, 2026 against src/app/_home-v2/_data/tools.ts CODING_MODELS, the WizardGenie coding picker ships eight frontier models with distinct shapes:
- Claude Opus 4.7 (Anthropic, tag Top tier) — the heavy reasoner. The model to reach for when the task is open-ended and the failure mode of a smaller model would be hallucinating an entire wrong architecture.
- Claude Sonnet 4.6 (Anthropic, tag Fast + smart) — the everyday workhorse. Cheaper than Opus, fast enough to keep flow, smart enough to ship a working Phaser prototype from a single prompt on most jam-sized projects.
- GPT-5.5 (OpenAI, tag Frontier) — the cross-check brain. Tends to catch logic mistakes the Anthropic models hand-wave through. Good as the “review the plan” voice in a multi-model loop even when Anthropic is doing the typing.
- Gemini 3.1 Pro (Google, tag 1M context) — the feed-the-whole-repo model. Use when the question is “where is this bug across forty files” rather than “what is the best algorithm here”.
- DeepSeek V4 Pro (DeepSeek, tag Budget) — the cheap executor. The model that should type when an expensive planner thinks. Per-token cost roughly an order of magnitude under the frontier; agentic loop quality landed at frontier-1 in 2026.
- Kimi K2.5 (Moonshot, tag 256K coding) — the long-file executor. Cheap, fast, holds an entire game project in a single context window, types into it without losing track of where it was.
- Grok 4.2 (xAI, tag 2M context) — the experimental brain. Reads enormous codebases in one shot. Good as a second opinion on the “what does this whole system do” question.
- MiniMax M2.7 (MiniMax, tag Agent-ready) — the tool-calling specialist. The model to pair with a long agentic loop where the agent has to call dozens of tools (file read, file write, terminal, browser, screenshot) without losing its plot.
All eight are reachable from the same WizardGenie tab and from the lower-level Sorceress Code chat-and-diff interface. The model picker is per chat, so a single project can route the heavy reasoning to Opus on Monday morning and the typing turns to DeepSeek V4 Pro on Monday afternoon without switching products. There is no separate Anthropic, OpenAI, Google, DeepSeek, Moonshot, xAI, or MiniMax subscription to manage on the Sorceress side; the trial keys ship with the account, and bring-your-own-key endpoints work for devs who already pay each vendor directly.
Which AI model is best for coding by task (decision tree for indie game devs)
The honest answer to which AI model is best for coding for an indie game dev in 2026 is a decision tree, not a leaderboard. Here is the mapping the WizardGenie lineup supports today:
- One-shot game scaffolds → Claude Opus 4.7. The prompt is “build a Phaser platformer with double-jump, coyote time, and a parallax background”. The model has to invent the whole architecture, pick the right loops, wire the input handler, structure the asset folders, and return a runnable HTML5 project on the first turn. Opus 4.7 is the right pick because the failure mode of a smaller model on this task is hallucinating a wrong architecture that compiles but does not run, and the cost of one Opus call is trivial against the cost of debugging a wrong architecture for an hour.
- Daily-flow coding → Claude Sonnet 4.6. The next two weeks of the project are a long sequence of small edits — add a new enemy, tune the jump physics, swap the sprite sheet, fix the camera. Sonnet 4.6 is the right pick because Opus is overkill on small edits, Sonnet keeps the iteration rhythm fast, and the cost difference compounds over hundreds of turns.
- Cross-checking the architecture → GPT-5.5. When the Anthropic models propose a system design, GPT-5.5 is a useful second voice that catches the things the Anthropic family hand-waves through. Route the “is this approach right” review prompt to GPT-5.5 even when the rest of the project lives on Anthropic.
- Whole-repo work → Gemini 3.1 Pro or Grok 4.2. When the question is “where is this bug across forty files” or “what does this codebase do”, context length matters more than peak reasoning. Gemini 3.1 Pro at 1M context handles most indie codebases in a single window; Grok 4.2 at 2M handles even the long-running projects that have grown past a year.
- Cheap executor in a Planner+Executor loop → DeepSeek V4 Pro, Kimi K2.5, or MiniMax M2.7. When the typing side burns 90% of the tokens in a long agent session, the executor must be genuinely cheap. All three are at roughly one order of magnitude under the frontier per token in 2026, and all three are good enough that the planner’s reviews catch the rare quality gap before it ships.
The decision tree is not five separate posts; it is one workflow. An indie dev shipping a game in 2026 hits all five branches across a single project. WizardGenie ships all eight models in one tab so the dev does not switch products at each branch — the model picker swaps inline per chat, the conversation history persists across model swaps, and the credit accounting flows through one credit pool. The sister post at Use Claude Code for Vibe Coding (Game-Dev Test) walks the Claude-specific slice; this decision tree covers the full eight-model lineup.
The Planner + Executor pattern — why two cheap-and-smart models beat one frontier
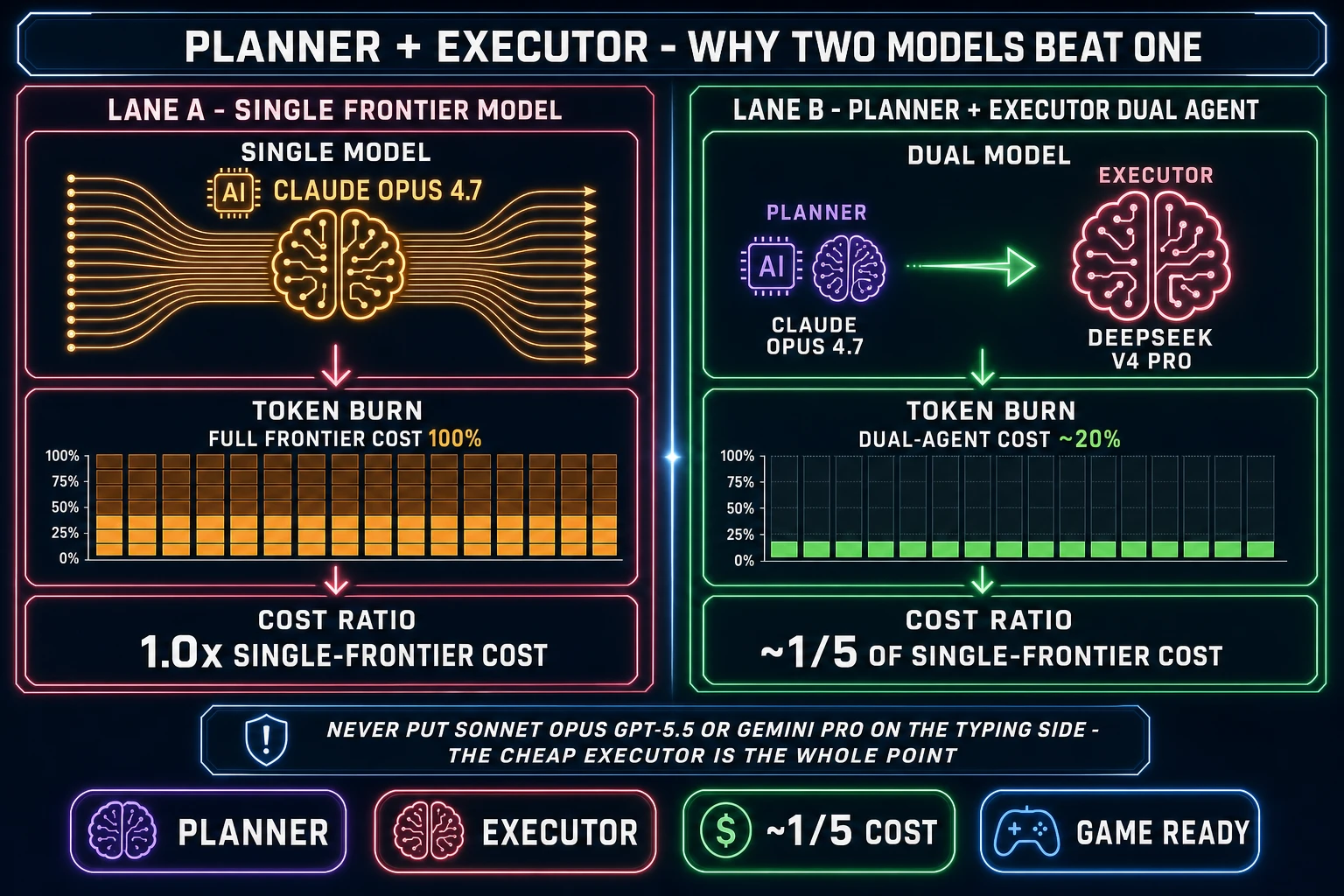
Planner + Executor is the dual-agent pattern where an expensive reasoning model (Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, or Grok 4.2) writes the plan and reviews the diffs while a cheap fast model (DeepSeek V4 Pro, Kimi K2.5, MiniMax M2.7, Gemini 3.1 Flash, or GPT-5.5 Mini) types out the code. The economic logic is the only thing in this whole piece that is genuinely mechanical:
- Per-token cost on a frontier model in 2026 sits roughly an order of magnitude above the same tokens on a budget model.
- The typing side of a long agent session burns roughly 90% of the tokens.
- Therefore moving the typing side to a budget model collapses the total cost to roughly one-fifth of running both sides on a frontier model, with the planning quality intact because the planner still reviews the diffs.
The trap that defeats the pattern is putting an expensive model on the typing side. Claude Sonnet 4.6 in/out tokens are not cheap by the budget-model standard; running Sonnet as the executor erases roughly 80% of the cost advantage the pattern is supposed to deliver. The rule for an indie dev shipping on a credit budget is: never put Sonnet, Opus, GPT-5.5, or Gemini 3.1 Pro on the typing side. The acceptable executors in 2026 are DeepSeek V4 Pro, Kimi K2.5, MiniMax M2.7, Gemini 3.1 Flash, GPT-5.5 Mini, and Claude Haiku 4.5 when it ships.
WizardGenie wires the dual-agent loop together inside one tab so the dev does not have to orchestrate two separate chats. The Planner+Executor mode is one of the dual-model superpowers documented on the WizardGenie page; the pattern is also reachable manually from Sorceress Code by swapping the model picker between turns. The cost ratio claim is “roughly one-fifth of single-frontier cost”, not “one-quarter”; one-quarter implies an expensive executor, which defeats the pattern.