
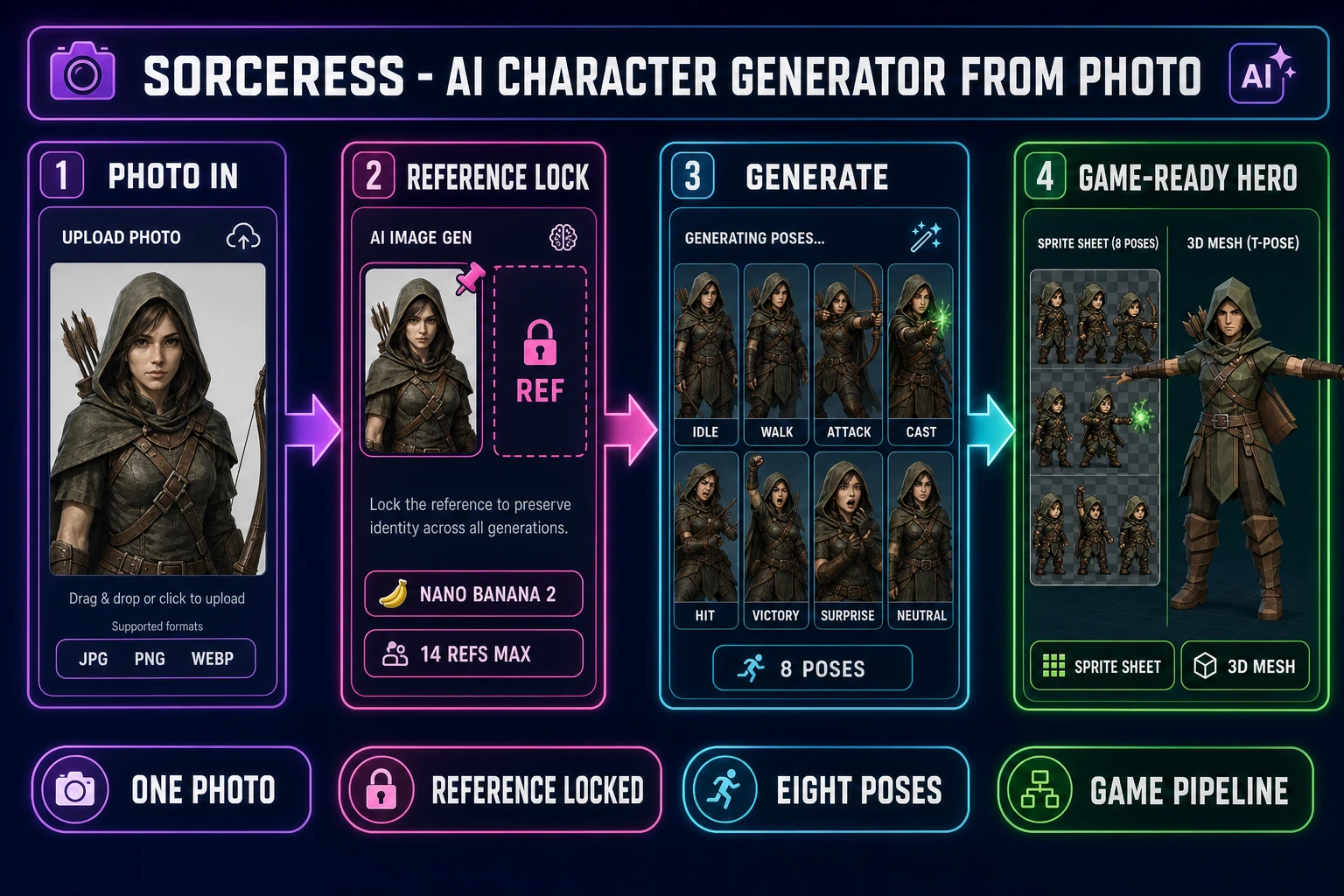
An AI character generator from photo takes a single reference image — a selfie, a friend’s photo with permission, an AI render from a different session, a 3D character screenshot — and produces eight on-model pose variants of the same hero. The text-only route fails this job by construction: each generation samples fresh noise, and the second prompt produces a different jawline, a different hair color, a different outfit silhouette, even when the words match exactly. The fix is the reference-image lock that every modern image model now ships, and the workflow built on top of it has a name searchers actually type into Google. This walkthrough covers what the AI character generator from photo workflow really does in 2026, which Sorceress models run it cleanly, the eight-pose recipe that produces a sprite-sheet-ready hero from a single source photograph, and how to bridge the photo-locked character into Quick Sprites for the sheet pack and into 3D Studio for the textured GLB. Verified June 5, 2026 against src/lib/models.ts, src/app/quick-sprites/page.tsx, src/lib/threed-models.ts, and the live /generate reference-image UI.
What an AI character generator from photo actually does in 2026
The phrase “AI character generator from photo” describes a specific kind of image-generation workflow, not a single tool. The common shape across every modern implementation is a diffusion model that accepts two inputs at sampling time: a text prompt and one or more reference images. The reference images are encoded into the same latent space the noise sampler is iterating against, and the diffusion process is biased toward latents that match the reference photo’s facial geometry, hair structure, skin tone, and outfit topology. The text prompt still drives pose, expression, action, and scene, but the model now has a commitment to a specific character that survives across calls.
That commitment is the difference between a photo prompt that produces eight different-looking strangers in eight different poses and a photo prompt that produces the same hero in eight different poses. For a game project, only the second outcome ships. An idle frame, a walk cycle, an attack pose, a casting animation, a hit reaction, and a victory pose all need to read as the same character or the sprite sheet looks like a glitched costume swap.
The technical underpinning is latent diffusion conditioned on reference embeddings — the same architecture that powers Stable Diffusion, Flux, Nano Banana, and the rest of the modern image-model lineup. The 2021 latent-diffusion paper from Rombach and colleagues is the academic primary source for the architecture; the practical takeaway is that reference conditioning is now a built-in feature on every flagship model and not an optional adapter the user has to install. The reference slot is where the photo goes; everything downstream is prompt engineering plus the right model pick.
How the reference-image lock actually works inside AI Image Gen
The reference-image input on Sorceress AI Image Gen at /generate exposes a single dashed slot that accepts JPG, PNG, and WebP files. Drop a portrait into the slot, and the next generation runs against that reference. The slot is persistent across consecutive prompts in the same session: the photo stays pinned until explicitly cleared, so the eight pose generations that follow all use it as the latent anchor without re-uploading. The maximum number of references depends on which model is selected in the picker:
- Nano Banana 2 (Google) — up to fourteen reference images. Verified at
refImages: { max: 14, param: 'image_input', ... }insrc/lib/models.tson June 5, 2026. Nine credits per generation at 1K resolution, twelve at 2K, seventeen at 4K. - Nano Banana Pro (Google) — up to eight reference images. The “Top tier” pick when the project needs maximum portrait quality. Verified at
refImages: { max: 8 }insrc/lib/models.ts. - Flux 2 Pro (Black Forest Labs) — up to eight reference images. Six credits base plus three per reference image. The model leans painterly and is the right pick when the prompt is heavy on stylized fantasy or hand-drawn aesthetic.
- GPT Image 2 (OpenAI) — up to ten reference images. The photoreal pick when the goal is a realistic in-game portrait rather than a stylized character.
- Seedream 5 Lite (ByteDance) — up to fourteen reference images at six credits per generation. The cheap iteration pick when the project needs to burn through a lot of pose variants.
- Grok Imagine (xAI) — up to five reference images. The creative-outlier pick.
Z-Image Turbo is the seventh model in the home-page rail (verified at src/app/_home-v2/_data/tools.ts lines 713 to 721 on June 5, 2026), but it does not currently accept reference images, so it is the wrong pick for an AI character generator from photo workflow even though its two-credit cost is the cheapest in the lineup. The pattern is to use Z-Image Turbo for prompt-only iterations during exploration and to switch to a reference-supporting model the moment the project commits to a specific hero.

Best Sorceress models for character-from-photo work
The seven-model lineup inside Sorceress AI Image Gen is not a generic pile of options — each model has a specific strength, and for character-from-photo work three of the seven are the genuine workhorses. The other four still play a role at the margins, but the recipe below is what actually ships.
- Default pick: Nano Banana 2. Nine credits per generation at 1K, twelve at 2K. Up to fourteen reference images. The strongest facial-stability lock in the lineup — the eyes, jawline, and outfit hold tighter across pose generations than any other model in the rail. The right starting point for almost every AI character generator from photo session unless the project explicitly needs a different aesthetic.
- Quality pick: Nano Banana Pro. Eighteen credits at 2K, thirty-three at 4K. Up to eight reference images. Tagged “Top tier” in the home-page model rail. The right pick when the hero portrait is the marketing key art and not just a sprite-sheet anchor — the extra resolution and detail justifies the credit cost when the output is for a Steam capsule, a launch trailer, or a key-art landing page.
- Stylized pick: Flux 2 Pro. Six credits base plus three per reference. Up to eight references. Leans painterly and hand-drawn. The right pick when the photo is a real-life input but the game art style is fantasy painterly or comic-style and the project wants the model to translate the photo into the painted aesthetic during the from-photo conversion.
- Photoreal pick: GPT Image 2. Seven credits at medium quality, seventeen at high. Up to ten references. The right pick when the game is a contemporary or near-future setting and the character should read as a photograph — the model holds photoreal facial detail across the eight pose variants.
- Iteration pick: Seedream 5 Lite. Six credits per generation at 2K. Up to fourteen references. The cheap-but-still-good model for exploring forty pose variations before locking the eight that ship. Useful when the project budget cares about per-generation cost and the prompt is uncertain enough that a lot of iteration is expected.
The pattern in practice is to start the photo lock on Nano Banana 2 (default), iterate with Seedream 5 Lite if the prompt needs more exploration, lock the final eight poses on Nano Banana 2 again for consistency, and only switch to Flux 2 Pro or GPT Image 2 when the aesthetic explicitly needs the model swap. Verified against src/lib/models.ts on June 5, 2026.



