A multi image to 3d model pipeline in 2026 takes four reference views of the same character or prop — a front view, plus optional left, back, and right views — and fuses them into one game-ready GLB inside a single browser tab. The four-view path is the honest answer to the single-image occlusion problem: when only one camera saw the character, the rear of the mesh is whatever the diffusion model decided was most plausible. With four views feeding the network, the rear is the actual rear. This guide walks the full multi image to 3d model pipeline inside Sorceress 3D Studio — from prepping the four reference frames in AI Image Gen, through the three multi-view-capable models (Meshy 6, Tripo v3.1, Tripo Smart Mesh), to the auto-rig handoff and the engine export. Every credit cost and capability verified against src/lib/threed-models.ts and src/components/studio/generate/GenerateTab.tsx on June 25, 2026.
src/lib/threed-models.ts on June 25, 2026.What multi image to 3d model actually means in 2026
The category covers any tool that takes multiple 2D reference images of the same subject — typically a front view plus one to three additional angles — and outputs a single polygon mesh with a UV unwrap and a baked texture atlas. The technical primitive is a multi-view diffusion-based mesh generator: a neural network trained on millions of paired multi-view-image-to-mesh examples that learns to fuse the silhouettes from every angle into one consistent 3D structure.
The dominant 2026 architecture extends single-image diffusion mesh generators with a cross-view attention layer that lets the network reason about the same surface point seen from multiple cameras simultaneously. Stage one learns the sparse 3D structure with full multi-view supervision — the silhouette from every camera, the volume that satisfies all four constraints, the gross spatial relationships. Stage two refines a structured latent into surface detail and texture, sampling the source images at every UV coordinate to produce textures that match the inputs faithfully. The diffusion model primitive is identical to the single-view path; the multi-view extension is in the conditioning signal.
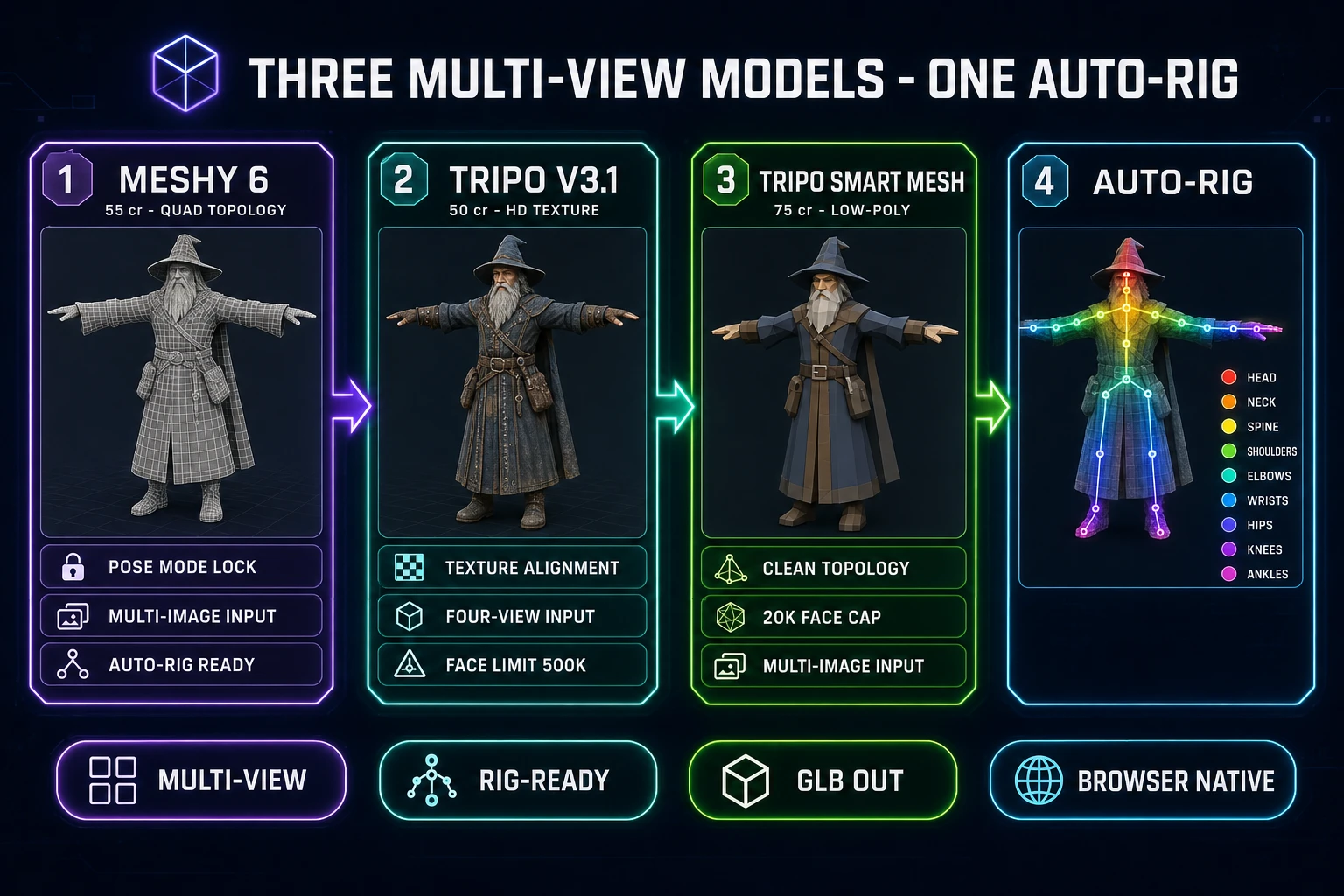
For an indie or solo developer, a multi image to 3d model in 2026 is the difference between a mesh that looks right from one angle and a mesh that looks right from every angle. The honest baseline: Sorceress 3D Studio ships nine total 3D models, three of which (Meshy 6, Tripo v3.1, Tripo Smart Mesh) accept the multi-image-to-3d input mode per the inputModes array on each model in src/lib/threed-models.ts. The four-slot uploader (front required, plus left, back, right optional) lives in src/components/studio/generate/GenerateTab.tsx and feeds the views straight to the chosen provider with no additional preprocessing step. Verified June 25, 2026.
Why four photos beat one — the multi-view advantage
A single-image-to-3D pipeline has to invent everything the camera did not see. The front of the character is grounded in real pixels; the back is whatever the diffusion model decided was most plausible. For a generic prop seen from any angle that does not require fidelity to a specific design, the invented rear is acceptable. For a hero character whose back is going to be on-camera in a third-person game, the invented rear is a problem. Game devs commonly run the same character through three or four single-image generations and pick the run where the rear hallucination matches the design — not because that is good practice, but because it is the only way to brute-force the occlusion problem with a single-view model.
Multi-view fuses the inputs at the diffusion-model level instead of brute-forcing at the output level. The network sees the silhouette from front, left, back, and right simultaneously and solves for the 3D volume that satisfies all four constraints at once. There is no rear hallucination because the rear is a real input. The texture is sampled from the actual rear pixels, not invented. The silhouette is consistent because the silhouette constraints are mathematically consistent.
The cost is in the inputs. A single-view bake takes one reference image; a multi-view bake takes two to four. For an AI-generated character, the cost is one extra trip through AI Image Gen per additional view, with the front view as the reference-image lock so the model preserves the same character identity from every angle. For a real-world capture, the cost is four phone snapshots from the cardinal angles. Either way, the marginal input cost buys a much better mesh — enough that for any character that will be auto-rigged and animated, the multi-view path is worth it. The photogrammetry tradition has known this since the 1990s; AI mesh generation in 2026 has finally caught up to the same insight.
How to fuse a multi image to 3d model with the honest 2026 browser stack
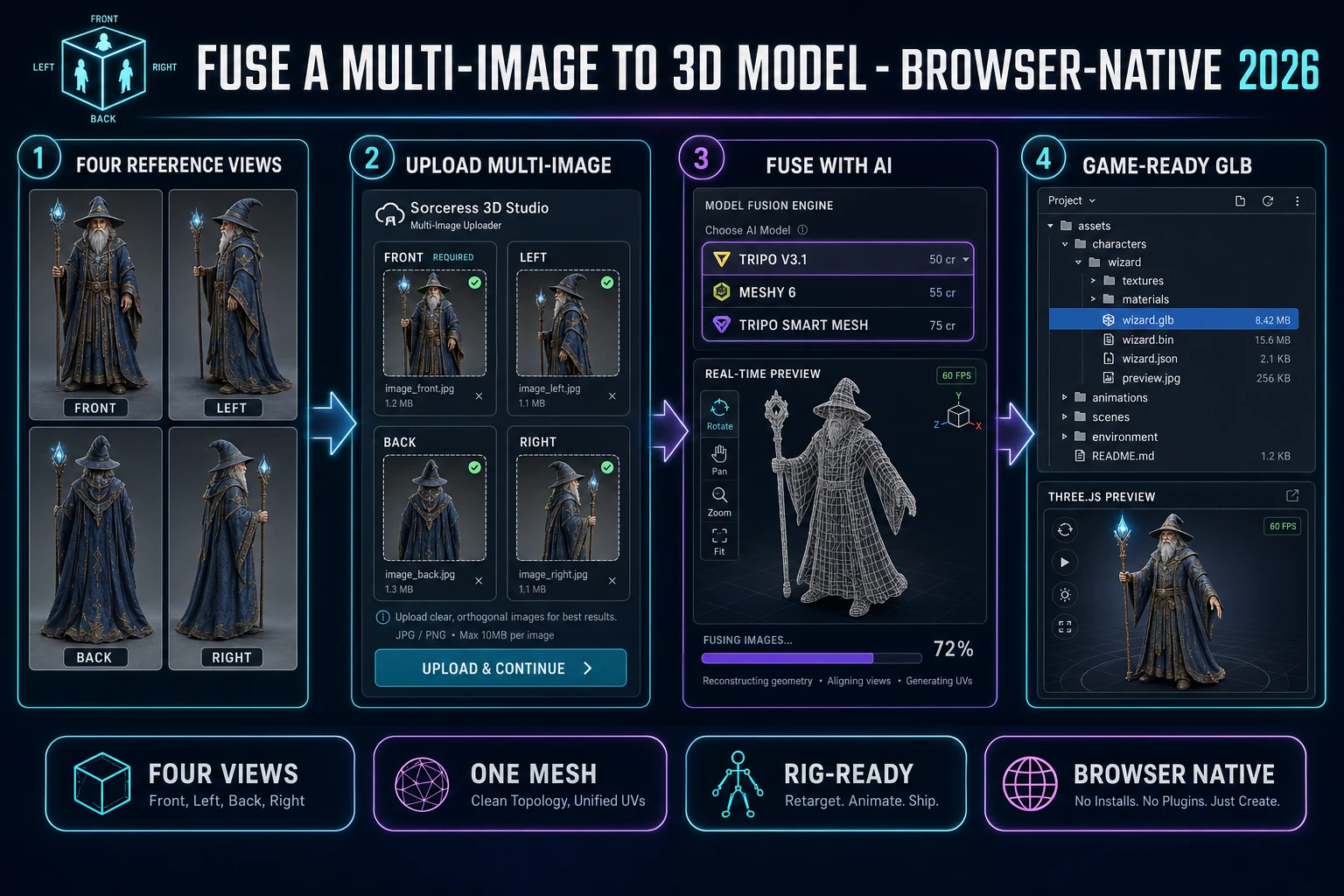
The full multi image to 3d model pipeline runs four steps in two browser tabs. Tab one is AI Image Gen for prepping the four reference views; tab two is 3D Studio for the multi-image upload, the model pick, and the export. No third-party software, no Photoshop, no Blender, no Maya seat, no FBX exporter plugin. Verified against the live UI on June 25, 2026.
- Step 1 — prep the four reference views. Open AI Image Gen at
/generate. Generate the front view first as the lock. Then generate left, back, and right views using the front view as a reference image so the same character identity carries across all four frames. - Step 2 — upload the views into 3D Studio multi-image mode. Open 3D Studio at
/3d-studio. Switch to the multi-image-to-3d input mode. Drop the four PNG, JPG, or WebP files into the four labeled slots: front (required), left (optional), back (optional), right (optional). - Step 3 — pick the multi-view model and run the bake. Choose Tripo v3.1 (50 credits with HD texture, the cheapest), Meshy 6 (55 credits with texture, the cleanest for humanoid characters), or Tripo Smart Mesh (75 credits, the cleanest low-poly). Submit the job; the browser tab does not block during generation.
- Step 4 — retopo, PBR-texture, and auto-rig the result. The completed bake lands in the gallery as a GLB. Optionally route into Material Forge for additional PBR maps, then into Auto-Rigging for a humanoid skeleton in the same browser tab.
The pipeline runs entirely in the browser. The four-step framing maps the entire multi image to 3d model workflow into one half-hour session for a hero character or one ten-minute session for a supporting prop — versus the days a hand-modeled, hand-rigged equivalent would take in a desktop 3D suite.

Step 1 — prep the four reference views (front, left, back, right) in AI Image Gen
The cleanest 2026 multi-view source pipeline starts with the front view. Open AI Image Gen at /generate and prompt for a front-facing, neutral-pose, clean-background reference image. Phrase the prompt with the character description, the pose constraint ("front-facing, arms slightly out from body, neutral expression"), and the background constraint ("clean white background, studio lighting, no shadows, no props"). Pick a model from the lineup that excels at character consistency — Nano Banana Pro and Nano Banana 2 lead the multi-frame consistency benchmarks; GPT Image 2, Seedream 5 Lite, Flux 2 Pro, Z-Image Turbo, and Grok Imagine round out the picker.
Lock the front view by using it as a reference image for the next three generations. The reference-image input is the same control that lets the model preserve a character across multiple poses; for multi-view, it preserves the character across multiple angles. Prompt for the left profile next: "left side profile of the same character, 90-degree side view, same pose, same outfit, same neutral background". Then the back: "rear view of the same character, facing away from camera, same pose, same outfit". Then the right profile: "right side profile, 90-degree side view from the right". Each generation drops into the gallery alongside the front view so all four are available for download.
The front view is the only mandatory upload at the next step — the 3D Studio multi-image uploader marks front as required and the other three slots as optional. A reasonable production pattern is to commit two views (front plus back) for fast asset turnover, three views (front plus left plus back) for anything that will be seen rotating in-game, and all four views for hero characters that will be on-camera in cinematics. The diffusion model accepts whatever subset is provided and fills missing angles from learned priors.