The 2026 search for a character AI voice generator has two distinct audiences. The first is an indie game developer staring at a script of 600 NPC dialogue lines, a budget that does not stretch to a voice-acting studio, and a calendar that says ship in eight weeks. The second is a hobbyist running a tabletop campaign, a visual-novel author, or a vibe-coder prototyping a fighting game who just wants every named character to actually sound like a character instead of an unread text box. Both groups land on the same answer: a text-to-speech engine that ships with character-archetype preset voices, supports voice cloning for the named cast, and exposes emotion tags so the same voice can sound calm, angry, or fearful at runtime. This post walks the full pipeline from a single dialogue line to a fully voiced game build, names the actual tools that produce each layer in 2026, and shows where Sorceress Speech Gen fits the indie workflow that historically required a paid studio session. Every model version, credit cost, and capability claim in this post was verified against the live Sorceress source on June 7, 2026.
What a character AI voice generator actually does in 2026
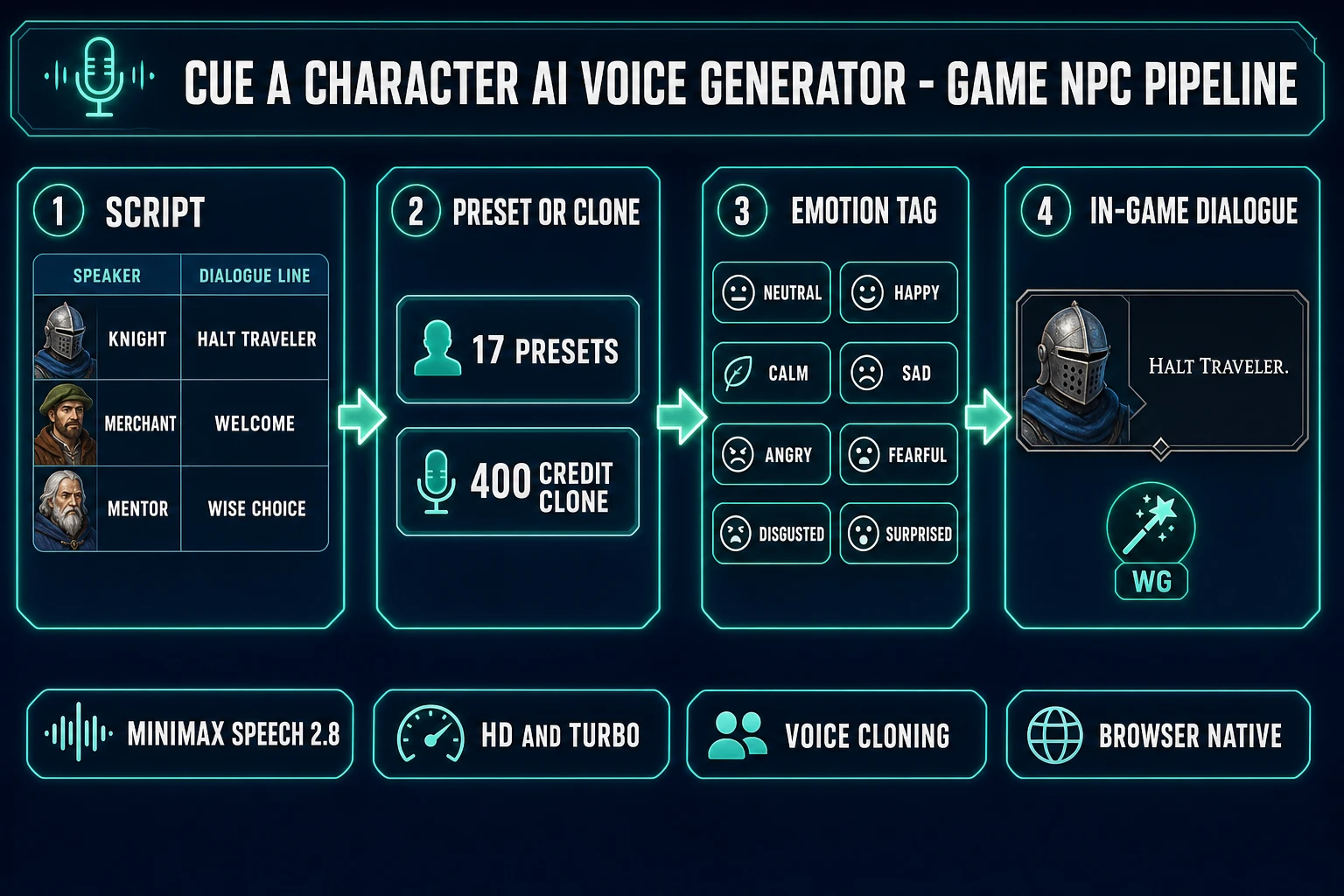
A character AI voice generator is a text-to-speech engine wrapped in three game-specific affordances: a library of preset voices that match common character archetypes (gruff knight, wise mentor, cheerful merchant, calm narrator), an emotion-tag layer that lets the same voice deliver the same line happy, sad, angry, or fearful, and a voice-cloning step that captures a custom voice from a short audio sample. The text-to-speech (TTS) primitive itself is described in the Speech synthesis Wikipedia entry — a deep model maps a sequence of phonemes plus pitch, duration, and energy targets to a sequence of audio samples, with mel-spectrogram or codec-token intermediates depending on the architecture. The 2026 generation of TTS models reads in under 250 ms end-to-end, replicates a target voice from 10–30 seconds of reference audio, and supports inline emotion tags or sound tags (laughs, sighs, breaths) without retraining.
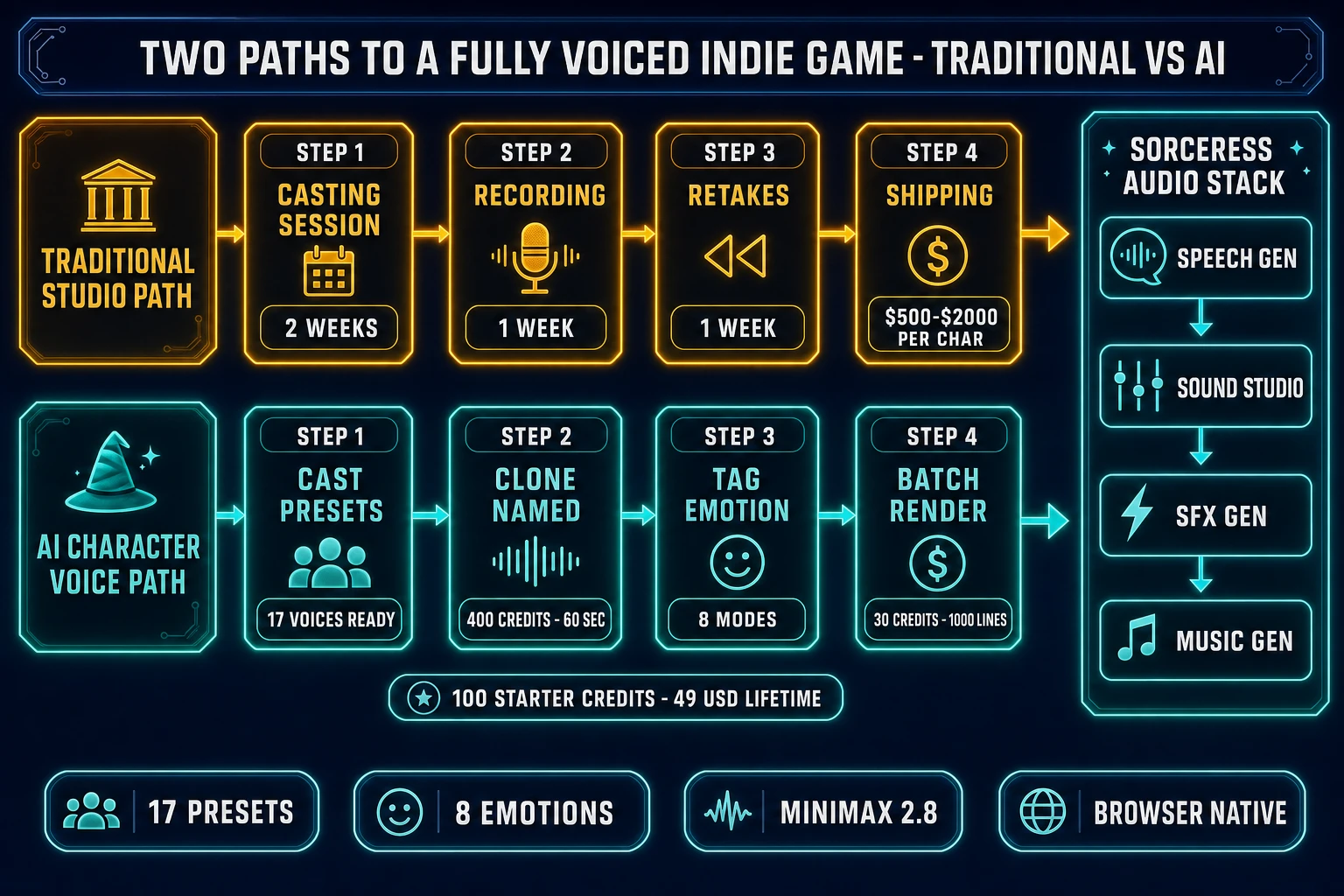
What this means for game development, per the Voice acting in video games Wikipedia entry: the historical bottleneck for indie voice acting was studio time. A single named character with 50 dialogue lines required a casting session, a recording session, retakes, and post-processing — commonly $500–$2000 per character at the indie tier. A character AI voice generator replaces every step except the final dialogue-review pass. The dialogue writer types the line, picks a preset voice or selects a cloned voice, tags the emotion, and renders. Iteration that used to take days now takes seconds.
The reader landing on “character ai voice generator” in 2026 is almost always asking three questions: can it sound non-robotic, can it stay consistent across a hundred lines, and can I afford to voice every named NPC. The honest answer to all three in 2026 is yes — with caveats around cloning ethics, hardware-output latency for real-time dialogue, and the practical difference between batch-script rendering and runtime streaming. The rest of this post unpacks each of those caveats and shows where the Sorceress Speech Gen path fits.
The three building blocks of every character voice (voice, emotion, clone)
Every 2026 character AI voice generator decomposes into the same three layers, and treating them as three separate decisions makes the indie pipeline tractable. The layers are universal across the major TTS rails (MiniMax Speech 2.8, Fish Audio, ElevenLabs, OpenAI tts-1-hd) — the differences sit in voice library size, emotion-tag fidelity, and voice-clone sample length, not in the underlying architecture.
- The voice — either a preset (a model-trained voice with a stable identity, typically described by gender, age range, and archetype: deep voice man, young knight, wise woman, lively girl) or a clone (a custom voice trained from a reference audio sample). Sorceress Speech Gen ships 17 preset voices verified against
src/app/speech-gen/page.tsxlines 156–174 on June 7, 2026: nine male presets (Deep Voice Man, Casual Guy, Patient Man, Young Knight, Determined Man, Decent Boy, Imposing Manner, Elegant Man, Friendly Person) and eight female presets (Wise Woman, Calm Woman, Inspirational Girl, Lively Girl, Lovely Girl, Abbess, Sweet Girl, Exuberant Girl). The naming scheme is deliberate — every preset reads like a character archetype, not a voice actor. - The emotion — a per-line tag that bends the voice toward a specific delivery without changing the underlying voice identity. The same Young Knight preset can deliver “Halt, traveler!” as Neutral, Happy, Angry, or Fearful. Sorceress Speech Gen exposes eight emotion modes verified against
page.tsxlines 179–188: Neutral, Happy, Calm, Sad, Angry, Fearful, Disgusted, Surprised. The same eight emotion taxonomy maps directly to the MiniMax Speech 2.8 platform rail perplatform.minimax.io/docs/guides/models-intro(seven user-facing emotions plus a Neutral default). - The clone — a custom voice trained from a recorded sample. The 2026 cloning floor has dropped to a 10–30 second reference per the MiniMax Speech 2.8 launch announcement; Sorceress Speech Gen allows samples up to 4 minutes 59 seconds per
MAX_CLONE_DURATION = 299atpage.tsxline 32, which lets the cloner train against a wider dynamic range and a richer prosody footprint. The trade-off is sample size capped at 20 MB perMAX_CLONE_SIZEat line 33 (the front-end auto-trims and converts to MP3 before upload). One clone costs 400 credits perVOICE_CLONE_CREDITSat line 31 — a single capital expense, not a per-line cost.
The mistake every newcomer makes is collapsing the three layers into one. They search “best character ai voice generator,” pick a single preset, render the entire script through it, and ship a flat game. The right pipeline treats each named NPC as a voice-plus-emotion-plus-(optional)-clone tuple, decided per character at script-prep time, and reused across every line that character speaks. Voicing 20 named NPCs with 50 lines each — 1,000 lines — on the Sorceress HD rail at an average 60 characters per line is 60,000 chars × (0.5 credits / 1,000 chars) = 30 credits, plus zero if every voice is a preset or 400 credits per cloned voice. That is the math indie voice acting has been waiting for.
The 17 preset voices inside Sorceress Speech Gen (game-archetype cast)
The preset library inside Speech Gen at /speech-gen is curated for game-character work. Verified on June 7, 2026 against the live source at src/app/speech-gen/page.tsx lines 156–174, the 17 presets break into the archetype categories every dialogue writer recognizes: the warrior (Deep Voice Man, Determined Man, Imposing Manner, Young Knight), the everyman (Casual Guy, Friendly Person, Patient Man), the youngster (Decent Boy, Lively Girl, Lovely Girl, Inspirational Girl, Sweet Girl, Exuberant Girl), the elder or mentor (Wise Woman, Abbess, Calm Woman), and the polished noble (Elegant Man). Each preset is a model-trained stable identity — the same voice every time you generate, with no drift across a 1,000-line script.
The casting workflow that fits an indie RPG: assign each named NPC to one preset at script-prep time, store the voice_id alongside the character name in your dialogue spreadsheet, and treat the preset library as a casting catalogue rather than a generic TTS pool. A working assignment for a 12-NPC small-village RPG: tavern owner = Patient Man, blacksmith = Imposing Manner, knight captain = Young Knight, wizard mentor = Wise Woman, abbess = Abbess, traveling merchant = Casual Guy, young apprentice = Decent Boy, princess = Inspirational Girl, court jester = Friendly Person, royal narrator = Elegant Man, village girl = Sweet Girl, retired adventurer = Determined Man. Twelve named NPCs assigned without burning a single voice-clone credit — the preset library handles the entire cast.
Per emotion the per-line cost stays the same. The EMOTIONS array (lines 179–188) supports Neutral, Happy, Calm, Sad, Angry, Fearful, Disgusted, and Surprised. The tavern owner welcomes a returning player with Patient Man + Happy. The same tavern owner warns about bandits with Patient Man + Fearful. The same character delivers a quest reward with Patient Man + Calm. Three lines, three deliveries, one voice identity locked across all of them. The cost of swapping the emotion is zero — no extra credits, no separate rendering call — because the emotion tag is part of the same /api/speech-gen request payload per the front-end source at page.tsx line 661 (const res = await fetch('/api/speech-gen', { ... })).

Voice cloning: one 30-second recording, unlimited lines (400 credits)
Voice cloning is the second half of the character AI voice generator stack and the part that separates a generic-sounding game from one that has a distinct vocal identity. The clone captures the timbre, breathiness, accent, and prosody of a reference voice from a short audio sample and stores the result as a reusable voice_id that behaves like a preset for every later generation. The technique sits on top of the speech-synthesis chain described in the Voice cloning Wikipedia entry — a speaker-embedding network extracts a fixed-length representation of the reference voice, and the downstream TTS model conditions every later output on that embedding.
The Sorceress voice-clone UX (verified at src/app/speech-gen/page.tsx lines 42–104, the processCloneAudio helper) is engineered to remove every barrier a non-audio-engineer would hit. The front-end accepts MP3 or M4A, accepts any other format by transparently transcoding through the Web Audio API plus the lamejs Mp3Encoder, auto-trims samples longer than 4 minutes 59 seconds (MAX_CLONE_DURATION = 299), and rejects anything past 20 MB (MAX_CLONE_SIZE). The clone cost is 400 credits flat per VOICE_CLONE_CREDITS at line 31 — a one-time capital cost per voice identity, not a per-line cost. After cloning, every TTS render using the cloned voice_id falls back to the standard per-1K-char rate: $0.50 per 1K chars HD per CREDITS_PER_1K_HD at line 28, or $0.30 per 1K chars Turbo per CREDITS_PER_1K_TURBO at line 29, with a 1-credit floor per generation per MIN_TTS_CREDITS at line 30.
The recording side of the workflow benefits from a teleprompter script the page ships at page.tsx line 114 onward. The script is roughly 60 seconds of varied speech designed to expose the voice across the full pitch and prosody range: rising intonation for questions, falling intonation for statements, emphasized syllables, common phonemes, and conversational fillers. The 2026 cloning-quality floor improves with longer samples up to about 90 seconds; beyond that, additional reference audio buys diminishing returns. For a named protagonist with 200 lines, the practical recommendation is one 60–90 second clone session against the teleprompter script, stored as a single voice_id, used across every line that character speaks.
The ethics layer matters and the post should not hand-wave it. A voice clone is a derivative of the reference voice — the cloned voice carries the speaker’s identity, and the speaker has a moral and (in many jurisdictions) legal claim on that derivative. The 2026 indie-game rule of thumb: clone voices you own (your own recorded voice for the protagonist, your co-developer’s for the rival, your audio-engineer friend’s for the mentor), or clone with an explicit written license from the speaker. Never clone a celebrity voice or a public-figure voice without consent — both the platform terms of service and the speaker’s likeness rights will end the project.