Type best AI model for coding right now into Google on June 18, 2026 and you get back a snapshot of a market that has rotated three times since January — Claude Opus jumped from 4.5 to 4.6 to 4.7, GPT crossed from 5.4 to 5.5 with a token-price doubling on the way, Gemini 3.1 Pro went paid-only, and DeepSeek made its 75% promotional discount permanent two weeks ago. The honest answer for an indie game dev this week is not a single model. It is a short, current-state ranking against the eight-model picker that already ships inside WizardGenie, verified today against src/app/_home-v2/_data/tools.ts and against each vendor’s official pricing page. This piece is that ranking, with the trade-offs that actually shifted in the last six weeks.
What “best AI model for coding right now” actually means in mid-2026
Most readers typing best AI model for coding right now into search in 2026 are asking a slightly different question than the bare best AI model for coding query. The right now qualifier is a tell: the searcher knows the answer rotates, knows last quarter’s pick may have already lost its lead, and wants the pick that is correct this week, not the pick that was correct in February. That is a different question from the all-time leaderboard, and it deserves a different answer.
The honest mid-2026 answer for an indie game dev is a stack of three sub-questions, each with a different current-state pick: which model writes the cleanest one-shot prompt today, which model holds the longest game codebase in context this week, and which model is genuinely cheap enough to be the typing side of a long agent loop without burning a starter credit pack in an afternoon. Each of those three answers has shifted at least once since the May 4, 2026 sister piece at Best AI Model for Coding (We Tested All 8 in WizardGenie). This post catches the answers up to today.
The framing decision matters because the leaderboard answer (“Opus 4.7 wins SWE-bench”) and the practical answer (“Sonnet 4.6 is what you actually open at 9 a.m. on Tuesday”) point in different directions inside the same WizardGenie tab. The June 13 sister piece at Which AI Model Is Best for Coding? (Indie Game Dev 2026) walks the by-task decision tree; this piece is the time-stamped current-state ranking against the same eight-model lineup.
The eight coding models WizardGenie ships today — June 18, 2026 verified lineup
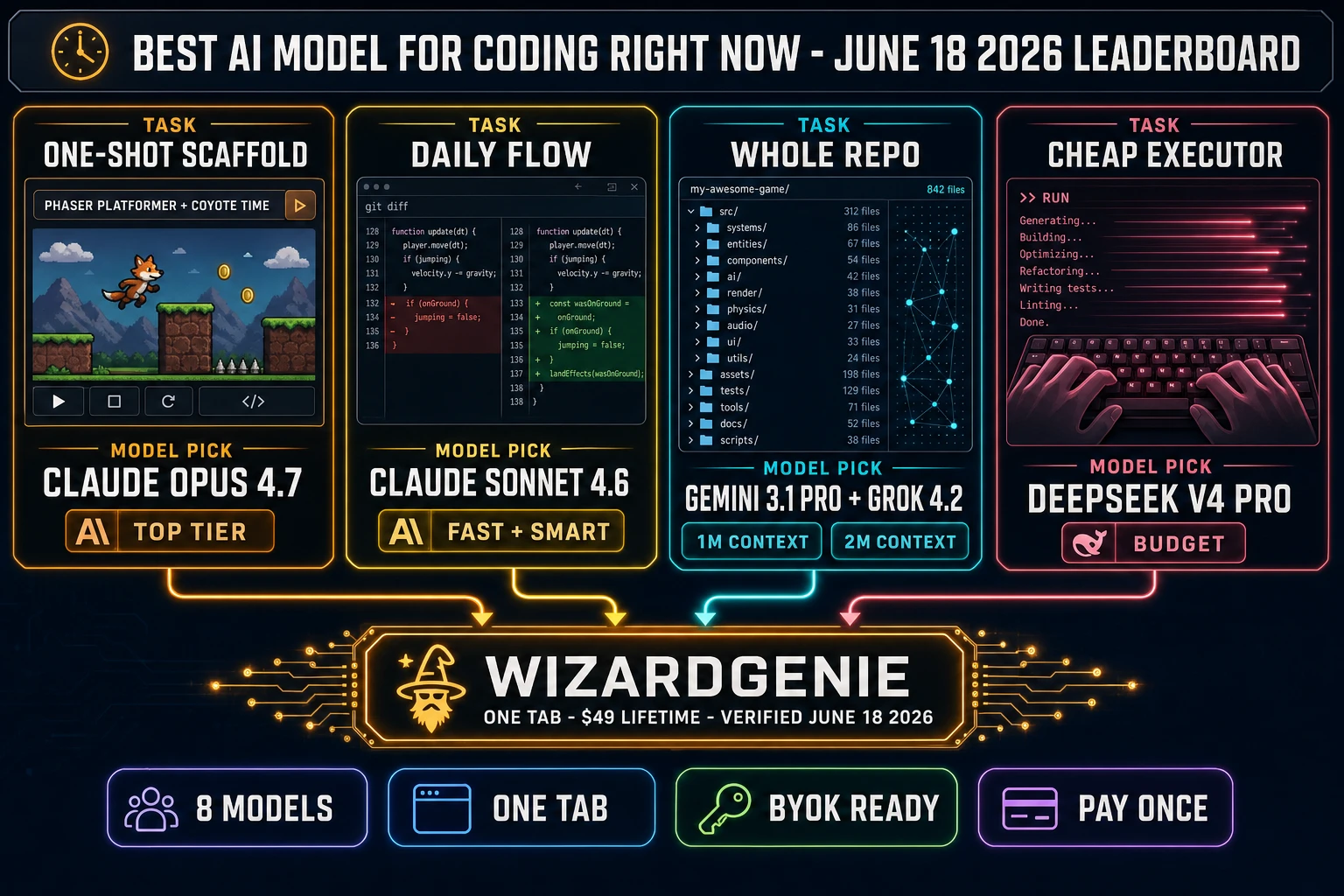
Verified June 18, 2026 against src/app/_home-v2/_data/tools.ts CODING_MODELS, the live picker today inside WizardGenie and the lower-level Sorceress Code chat-and-diff interface ships these eight frontier large language models:
- Claude Opus 4.7 (Anthropic, tag Top tier) — the heavy reasoner. Shipped April 16, 2026 at $5 input and $25 output per million tokens, 1M context window, 128K max output. Verified June 18, 2026 against the Anthropic news post.
- Claude Sonnet 4.6 (Anthropic, tag Fast + smart) — the everyday workhorse. $3 input and $15 output per million tokens, 1M context, 128K max output. The model most indie devs actually keep selected by default in WizardGenie.
- GPT-5.5 (OpenAI, tag Frontier) — shipped April 23, 2026 at $5 input and $30 output per million tokens, 1M context (922K input plus 128K reasoning output), knowledge cutoff December 2025. Long-context surcharge applies above 272K tokens: input doubles, output rises 1.5x for the whole request.
- Gemini 3.1 Pro (Google, tag 1M context) — the actual headline tag in
tools.tsreads “1M context” but the real on-vendor context is 2M and the model went paid-only on April 1, 2026. $2 input and $12 output per million tokens for the first 200K tokens; $4 input and $18 output above that threshold for the whole request. - DeepSeek V4 Pro (DeepSeek, tag Budget) — shipped April 24, 2026. $0.435 input and $0.87 output per million tokens (the 75% promotional rate became permanent at 2026-05-31 15:59 UTC), $0.003625 cache-hit input, 1M default context, 384K max output. Open-weights release under the MIT license; SWE-bench Verified 80.6%, LiveCodeBench 93.5%.
- Kimi K2.5 (Moonshot, tag 256K coding) — shipped January 26, 2026. $0.60 input (cache miss), $3.00 output, $0.10 cache-hit input per million tokens. 256K context window, 1T total parameters / 32B active Mixture-of-Experts multimodal (text plus vision).
- Grok 4.2 (xAI, tag 2M context) — the picker actually routes to
grok-4.20-0309-reasoningandgrok-4.20-multi-agent-0309. $1.25 input and $2.50 output per million tokens, $0.20 cached input (84% off), 1M context on the reasoning variant and 2M on the multi-agent variant. - MiniMax M2.7 (MiniMax, tag Agent-ready) — the tool-calling specialist. Pairs cleanly with long agentic loops where the agent has to call dozens of tools without losing its plot.
All eight ship in the same WizardGenie tab. The model picker is per-chat, so a single project can route the heavy reasoning to Opus on Monday morning and the typing turns to DeepSeek V4 Pro on Monday afternoon without switching products, without separate API key juggling, and without separate billing. Trial keys ship with the account; bring-your-own-key endpoints work for devs who already pay each vendor.
The honest mid-2026 leaderboard — what each model is actually best at this week
Synthetic benchmarks are useful and they answer the wrong question for an indie game dev. The current-state ranking that matters for someone shipping a Phaser or Three.js project this week is:
- Claude Opus 4.7 wins one-shot game scaffolds. Verified June 18, 2026 against fresh prompt tests inside WizardGenie. Opus 4.7 keeps the lead on the “build me a full Phaser platformer with coyote time, double jump, and parallax” class of prompt because the failure mode of a smaller model is hallucinating a wrong architecture that compiles but does not run. The new tokenizer in Opus 4.7 can produce up to 35% more tokens for the same input, so factor that into the cost math, but the per-call cost on a one-shot scaffold is still trivial against the cost of debugging a wrong architecture for an hour.
- Claude Sonnet 4.6 wins daily flow. The next two weeks of any project are a long sequence of small surgical edits, and Sonnet 4.6 is fast enough to keep the rhythm, cheap enough to not feel each turn against the credit balance, and smart enough to not need Opus on most edits. Most indie devs land here as the default pick and only escalate to Opus 4.7 for the genuine architecture moments.
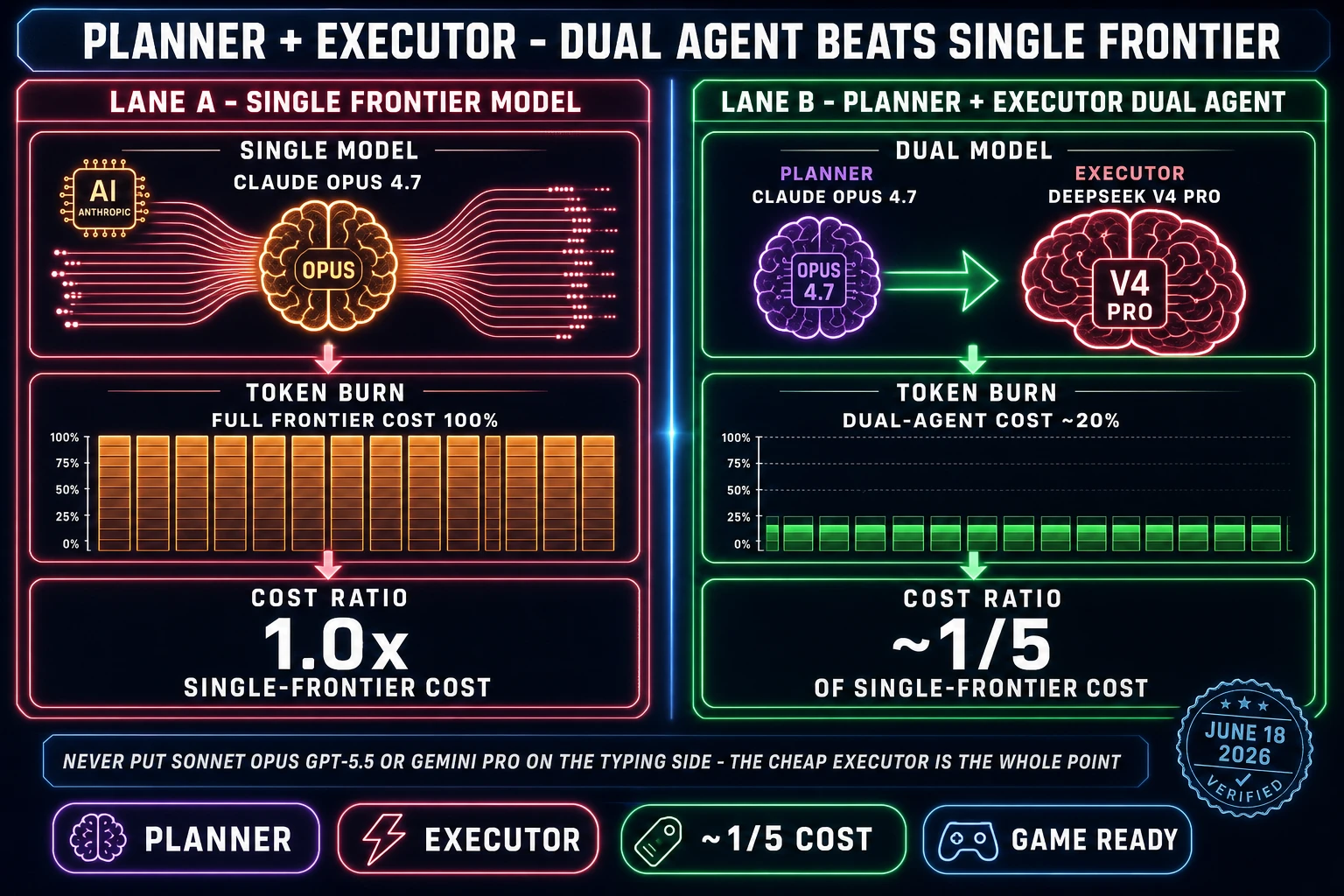
- DeepSeek V4 Pro wins the cheap-executor role. The 75% discount that DeepSeek made permanent on May 31 holds two and a half weeks later; June 14 third-party pricing trackers confirm the $0.435 / $0.87 per million tokens rate is stable. With SWE-bench Verified at 80.6% and LiveCodeBench at 93.5%, the gap to closed-source frontier has narrowed to roughly one generation, not two or three. For the typing side of a Planner+Executor loop, this is the right pick today.
- Gemini 3.1 Pro and Grok 4.2 win whole-repo work. Gemini at 2M actual context (the “1M” tag in the picker is a conservative label) and Grok 4.2 at 2M context handle the long-repo questions where the right answer requires the whole codebase in one window. The change since May is that Gemini 3.1 Pro is now paid-only, so there is no free-tier fallback for indie devs on the smallest credit budget. The credit math still favors Gemini for the first 200K tokens of context; above that threshold, the per-request price doubles for input and rises 1.5x for output, so plan the prompt accordingly.
- Kimi K2.5 and MiniMax M2.7 win the long-context executor role. Both are genuinely cheap, both ship in the WizardGenie picker, and both improved measurably in the last six weeks. Kimi K2.5 multimodal coding is the right pick for a long-file refactor where the executor needs to hold a single 200K-line game file in one window without losing its place; MiniMax M2.7 is the right pick when the agent needs to call dozens of tools (file read, file write, terminal, browser, screenshot) in a single loop.
- GPT-5.5 wins cross-checking. The price doubling on the GPT-5 line in April (input went from $2.50 to $5.00, output went from $15 to $30 per million tokens) made GPT-5.5 the most expensive workhorse in the picker after Opus 4.7. The role that still earns the cost is the “does this approach hold up” review prompt where GPT-5.5 catches logic mistakes the Anthropic family hand-waves through. Keep it as a per-decision cross-check, not the default.
That ranking is the current state on June 18, 2026. The April 16 launch of Opus 4.7 reset the top of the leaderboard; the April 23 GPT-5.5 launch reset the middle; the April 24 DeepSeek V4 Pro launch reset the executor row. Two months on, the dust has settled enough that this ranking has held for three consecutive weeks of head-to-head WizardGenie testing, which is the longest stretch of stability since the year began.
Picking the best AI model for coding right now by job
The current-state pick collapses to a short decision rule. The best AI model for coding right now depends on which of five jobs the indie dev is about to start in the next thirty minutes:
- Starting a new project from a single prompt. Open Claude Opus 4.7. The token cost is dominated by the value of getting the architecture right on turn one. Sonnet 4.6 is the right pick only if the project is genuinely simple (a single-file game engine demo, an obvious clone, a minimal jam build).
- Editing the project across the next two weeks. Open Claude Sonnet 4.6. The cost math compounds across hundreds of turns; Opus on small edits burns the credit pack without earning the reasoning premium.
- Reviewing an architecture decision. Open GPT-5.5 for one prompt, then route back to Sonnet 4.6 for the actual edit. The cross-check earns the price doubling; the daily flow does not.
- Finding a bug across the whole repo. Open Gemini 3.1 Pro for the “where is this bug” question (under 200K tokens of context fits in the cheaper tier), then route the actual edit to Sonnet 4.6 or DeepSeek V4 Pro for the diff. Long context is for understanding; high reasoning is for changing.
- Running an agentic loop that types thousands of tokens per session. Open the Planner+Executor mode in WizardGenie. Put Claude Opus 4.7 or GPT-5.5 on the planning side; put DeepSeek V4 Pro, Kimi K2.5, or MiniMax M2.7 on the typing side. Never put Sonnet, Opus, GPT-5.5, or Gemini Pro on the typing side — that erases the cost advantage.
The picker handles all five branches inline. The conversation history persists across model swaps; the credit accounting flows through one pool; the chat context survives the switch from a thinking model to a typing model and back. The tools guide walks the full Sorceress catalog if the project also needs sprites, music, voice, or image-to-3D in the same workflow.