
This is the verified AI coding API pricing chart for every model that matters in 2026 — Claude, GPT-5, Gemini, DeepSeek, Grok, Kimi, Qwen, MiniMax, and Cursor Composer 2 — with input, output, cache hit, cache miss, and vision-support data pulled straight from each vendor’s official rate card on May 4, 2026. That includes this week’s launches: DeepSeek V4 (April 24), Kimi K2.6 (April 20), and Grok 4.3 (April 30).
The chart sits at the top because that’s the only number most readers actually need. Below it: a per-model play-by-play with the AI coding API pricing context for game-dev workflows specifically — which model earns its slot on which turn. WizardGenie bundles all the relevant ones behind a single picker so you can rotate through them without rewiring your project for each switch.
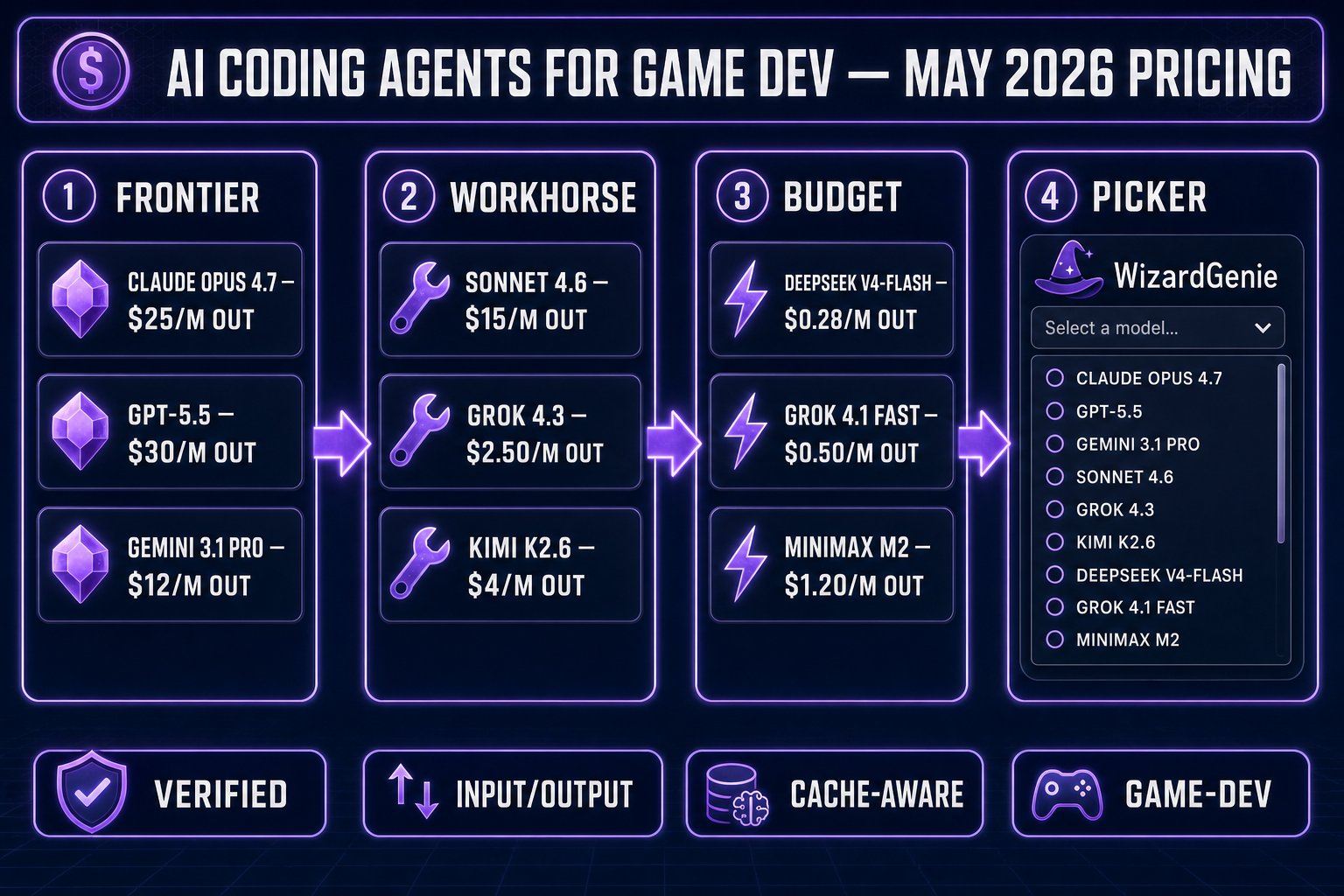
AI coding API pricing: the complete chart
All prices are per million tokens (MTok), in USD, on each vendor’s standard public API tier. “Cache hit” is what you pay when the prompt prefix is already cached on the vendor’s side. “Cache write” is what you pay to put a prefix into cache the first time. Numbers were pulled from each vendor’s published pricing page on May 4, 2026 — before you commit to a long session, double-check the live page for your account, since rates shift quietly.
| Model | Input | Cache hit | Cache write | Output | Vision | Context |
|---|---|---|---|---|---|---|
| Claude Opus 4.7 | $5.00 | $0.50 | $6.25 (5m) / $10 (1h) | $25.00 | Yes | 1M |
| Claude Sonnet 4.6 | $3.00 | $0.30 | $3.75 (5m) / $6 (1h) | $15.00 | Yes | 200K (1M opt-in) |
| Claude Haiku 4.5 | $1.00 | $0.10 | $1.25 (5m) / $2 (1h) | $5.00 | Yes | 200K |
| GPT-5.5 | $5.00 | $0.50 | auto | $30.00 | Yes | 400K |
| GPT-5.5 Pro | $30.00 | — | — | $180.00 | Yes | 400K |
| GPT-5.4 | $2.50 | $0.25 | auto | $15.00 | Yes | 400K |
| GPT-5.4 mini | $0.75 | $0.075 | auto | $4.50 | Yes | 400K |
| Gemini 3.1 Pro (≤200K prompt) | $2.00 | $0.20 | $4.50/M-hr storage | $12.00 | Yes | 1M |
| Gemini 3.1 Pro (>200K prompt) | $4.00 | $0.40 | $4.50/M-hr storage | $18.00 | Yes | 1M |
| Gemini 3.1 Flash-Lite | $0.25 | $0.025 | $1.00/M-hr storage | $1.50 | Yes | 1M |
| DeepSeek V4-Pro (75% off promo) | $0.435 | $0.003625 | auto on disk | $0.87 | Yes | 1M |
| DeepSeek V4-Pro (standard, post-promo) | $1.74 | $0.0145 | auto on disk | $3.48 | Yes | 1M |
| DeepSeek V4-Flash | $0.14 | $0.014 | auto on disk | $0.28 | Yes | 1M |
| Grok 4.3 | $1.25 | $0.31 | auto | $2.50 | Yes (+ video) | 1M |
| Grok 4.20 | $2.00 | $0.20 | auto | $6.00 | Yes | 2M |
| Grok 4.1 Fast | $0.20 | $0.05 | auto | $0.50 | Yes | 2M |
| Kimi K2.6 | $0.95 | $0.16 | auto | $4.00 | Yes | 256K |
| Kimi K2.5 | $0.60 | $0.10 | auto | $2.50 | Yes | 256K |
| Qwen3 Coder | $0.30 | — | — | $1.50 | Variant | 1M |
| MiniMax M2 | $0.30 | $0.03 | $0.375 | $1.20 | Yes | 256K |
| Cursor Composer 2 | $0.50 | — | — | $2.50 | — | — |
| Cursor Composer 2 Fast | $1.50 | — | — | $7.50 | — | — |
How to read this chart (it isn’t just “cheap = good”)
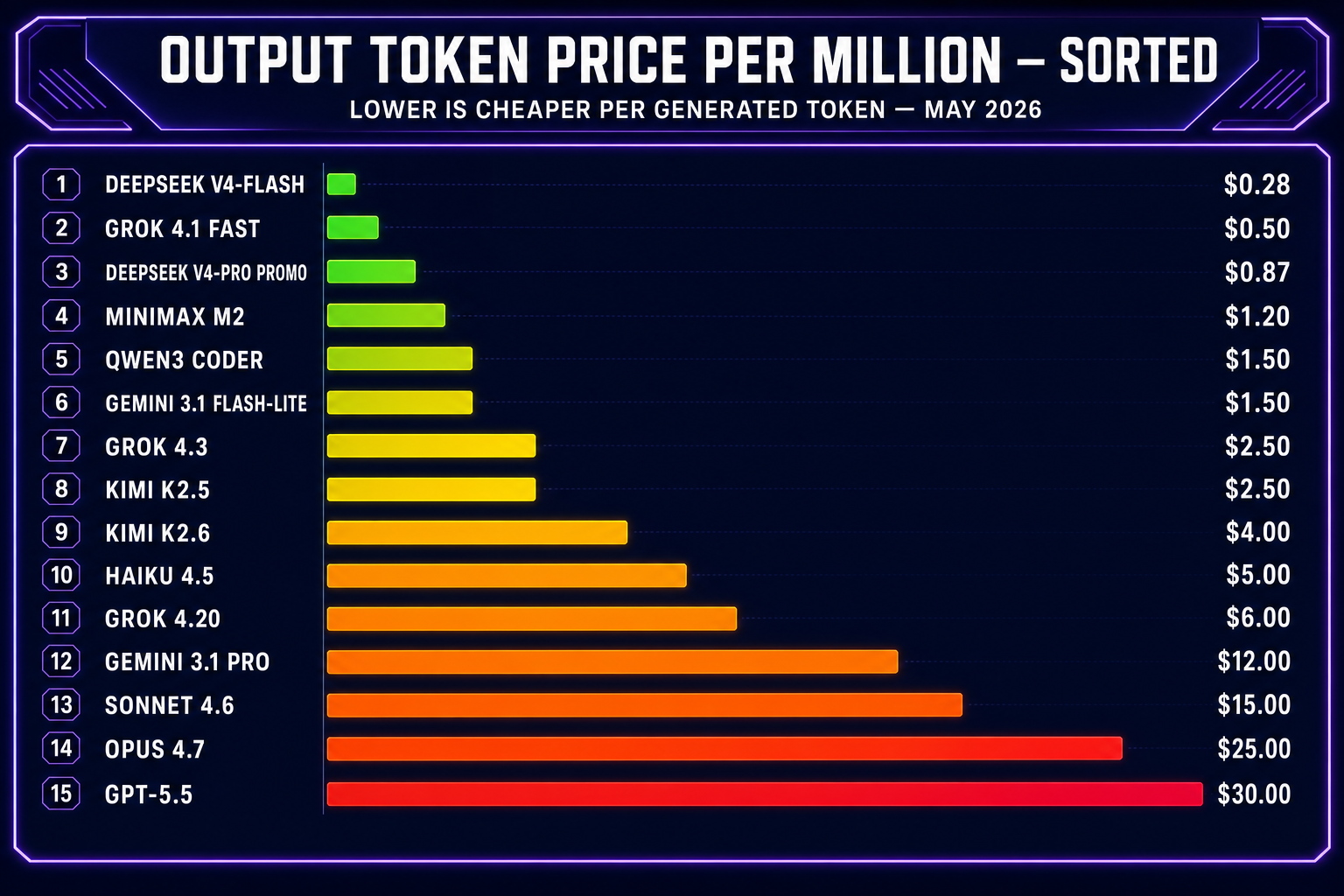
- Output dominates the bill. Coding agents emit ~3–10× more output than input on a typical agentic turn (the diff is shorter than the file the model reads). Output token price is therefore the number that actually shapes your invoice.
- Cache hits are the secret savings lever. Every vendor that lists a “cache hit” price is offering an 80–90% discount on prompt prefixes that haven’t changed since the last call. For agentic loops where the system prompt and project files barely change between turns, that discount applies to most of your input volume.
- Vision matters more than people think. Game dev work is full of “look at this screenshot — the wizard is clipping through the floor”. A model without vision can’t help. Most frontier models support image input; Grok 4.3 added video input on April 30. Plain Qwen3 Coder text variant is text-only; vision-capable Qwen variants are sold separately.
- Context window only matters above a threshold. Phaser jam games are 2K–10K lines; any 200K-context model holds them whole. Three.js projects with shaders, scene graphs, and post-processing can climb past 100K tokens fast — that’s where 1M / 2M context windows justify their pricing premium.
- Promotional pricing is real but temporary. DeepSeek V4-Pro is 75% off through May 31, 2026 — that’s the effective rate for the next four weeks. After that you pay the standard $1.74 / $3.48. Plan your benchmarks around this so you don’t end up locked into a model that’s about to quadruple in price.
- Batch APIs are 50% off. Anthropic, OpenAI, Google, and xAI all offer a batch tier at half price for non-interactive workloads. Most agentic coding sessions can’t use batch — interactive latency matters — but it’s worth knowing for offline prep work like asset descriptions or doc generation.
Anthropic: Claude Opus 4.7, Sonnet 4.6, Haiku 4.5
Anthropic’s lineup is the cleanest pricing ladder of any vendor: a tight 5× factor between each tier. Opus 4.7 (released April 16, 2026) is the frontier reasoner — the model to spend on when the agent is making real design decisions about your game (game-feel, scoring rules, win conditions, refactors that touch four files at once). At $5 input / $25 output it’s expensive, but with prompt caching the input side drops to $0.50, and Opus 4.7 ships with the full 1M-token context window at standard pricing — no opt-in, no surcharge. On agentic loops where the same files get re-read on every turn, that combination is doing serious work.
Sonnet 4.6 is the workhorse: roughly one-fifth the cost of Opus, and on most coding tasks it returns about 90% of Opus’s quality. For routine refactors, adding HUD elements, wiring up new entities to existing systems — Sonnet is the right default. The new tokenizer in Opus 4.7 (per the published Claude API pricing page) uses up to 35% more tokens for the same text vs. older Anthropic models, so a “cheaper” output rate doesn’t always mean a cheaper request — keep that in mind when comparing per-Mtok numbers across generations.
Haiku 4.5 at $1 / $5 is the smallest member that’s still serious enough to ship with. For purely mechanical work — sprite path edits, constant tweaking, tiny UI patches — Haiku is fine. It’s also a legitimate executor in a Planner+Executor pair if you want to stay inside the Anthropic ecosystem (more on the pattern below).
OpenAI: GPT-5.5, GPT-5.4, GPT-5.4 mini
OpenAI’s GPT-5 family is structured like Anthropic’s: a flagship, a value tier, and a mini. The wrinkle is that GPT-5.5’s output token rate is $30/MTok — the highest in the entire chart for a generally available model. Per OpenAI’s published API pricing, cached input tokens are 90% off across the GPT-5 line, which materially changes the math for any session where the system prompt and project context get reused turn after turn (which is every coding session worth caring about).
One detail that catches people: for prompts above 272K tokens, GPT-5.5 input pricing doubles and output pricing rises 1.5×. If your project is already past 200K tokens of context, plan around the threshold or switch to a model that prices long context flat (Opus 4.7 at 1M flat, Gemini 3.1 Pro on its tier system).
GPT-5.5 wins one-shot vibe-code prompts. Drop a paragraph describing a game, and GPT-5.5 commits to architectural choices without three rounds of clarifying questions. That’s exactly what you want when you’re feeling out a prototype in five minutes. It’s the wrong model for a 30-turn session where every turn costs $0.10 of output — that’s where GPT-5.4 (half the price) or 5.4 mini (one-sixth) take over. GPT-5.5 Pro at $30 / $180 sits in a different league entirely; only reach for it on tasks where every other model has actually failed to produce a correct answer, not as a default coding agent.
GPT-5.4 mini at $0.75 / $4.50 is one of the better priced “smart enough to actually use” coding agents in the whole chart. It’s an acceptable executor in a Planner+Executor pair if you’re already paying OpenAI bills and don’t want to add a second vendor.



