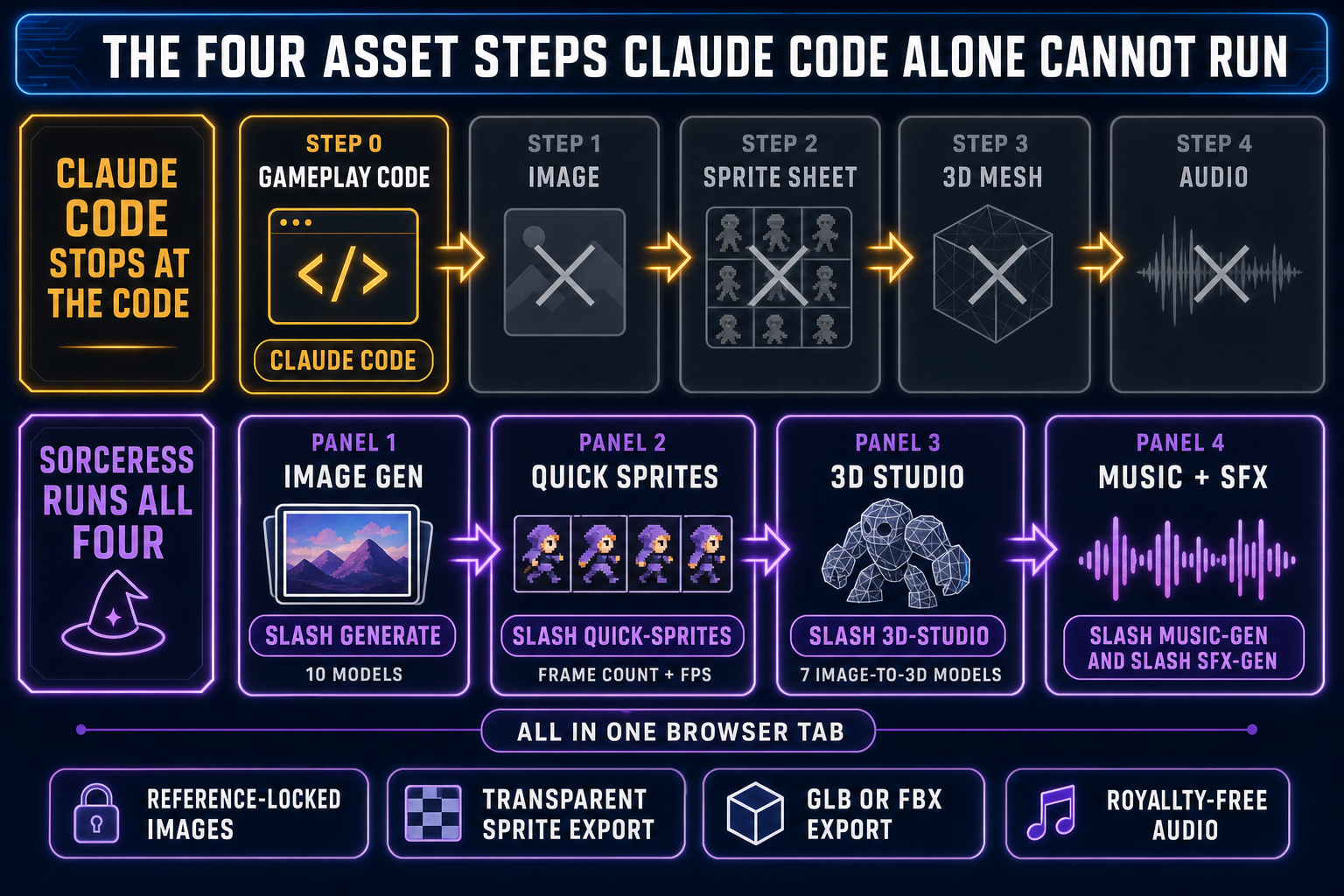
Is Claude Code vibe coding? The short answer is yes, but only on the surface where the dev actually adopts the vibe-coding posture — describe intent, accept the diff without line-editing it, run, watch the result, paste the next prompt — instead of using Claude Code as a traditional senior-dev assistant. Anthropic ships Claude Code as a generic agentic CLI; the “vibe coding” label belongs to the workflow, not the tool. For game devs the practical follow-up is the more important question: Claude Code vibe-coding a browser game gets you the gameplay code in minutes, then strands you at the asset wall — sprites, 3D meshes, music, sound effects — that the CLI is not designed to render. This post pulls Karpathy’s definition (February 2, 2025 origin tweet), the May 2026 state of Claude Code (v2.1.139, May 11, 2026, 122,000+ stars on GitHub), and the four-step games gap together into a single read. Verified May 16, 2026 against the Anthropic pricing aggregator listings, the anthropics/claude-code GitHub release tags, and the WizardGenie model lineup in src/app/_home-v2/_data/tools.ts.

Is Claude Code vibe coding by Karpathy’s original definition?
Andrej Karpathy coined the term on February 2, 2025 on X with about 4.5 million views and a single paragraph that the field has been quoting since. The posture has four moves: “I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.” Karpathy was using Cursor Composer routed to Anthropic’s Sonnet, often controlling it through voice with SuperWhisper, accepting diffs without reading them line by line, and pasting error messages straight back into the model. Independent analyst Simon Willison picked the term up four days later. The Collins Dictionary named “vibe coding” the Word of the Year for 2025. The term escaped the dev-Twitter bubble somewhere around May.
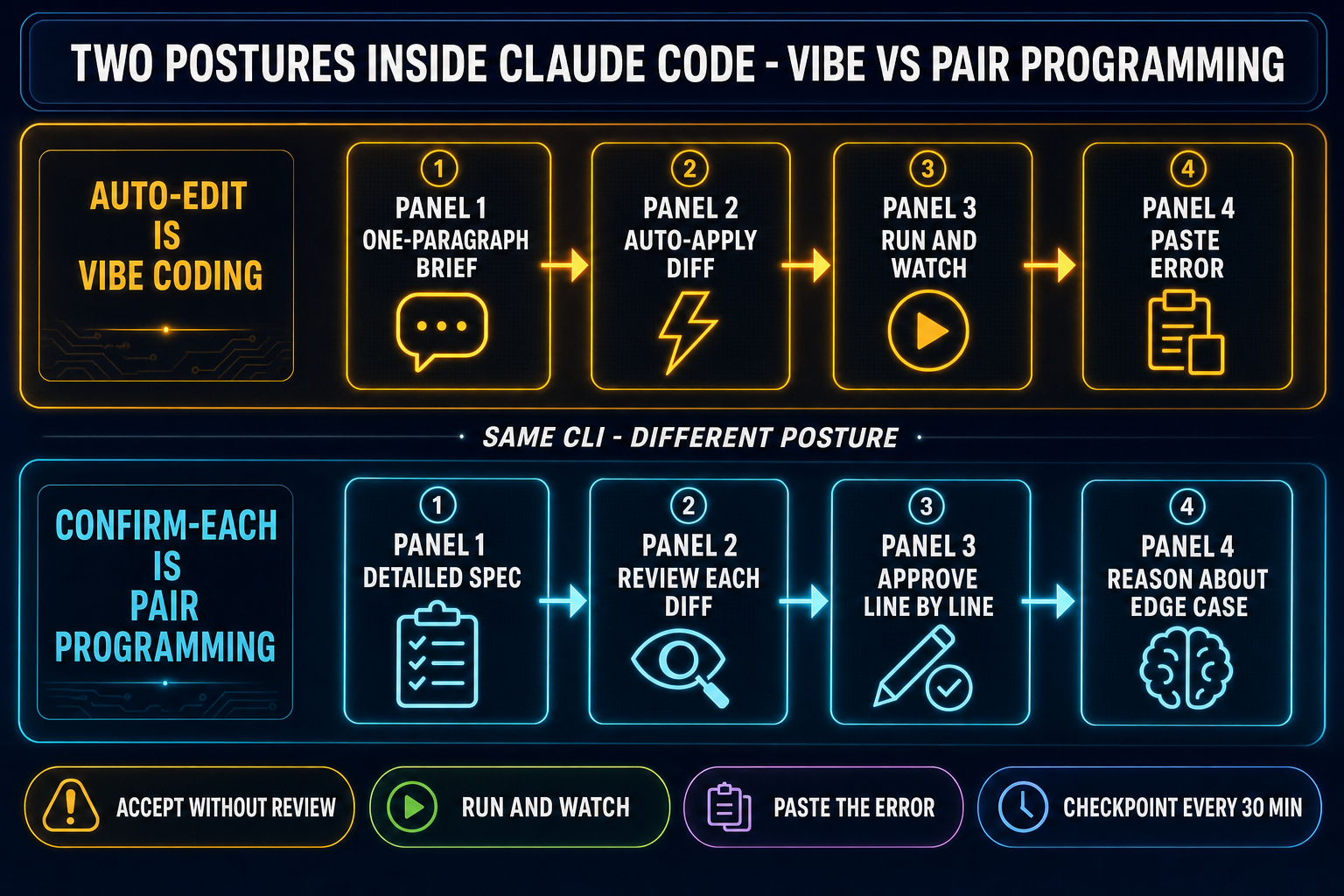
Claude Code, on the surface where Anthropic actually ships it, is a terminal CLI installed with one command (claude in your shell) that reads your workspace, applies edits, runs shell commands, and orchestrates tool use through an agentic loop. The GitHub releases for anthropics/claude-code are on v2.1.139 as of May 11, 2026, the 108th release in roughly a year. The CLI is a generic agentic coding system. It does not enforce a posture. A dev who reviews every diff line by line and asks Claude Code to explain its reasoning before accepting changes is using Claude Code in the traditional senior-engineer pair-programming style, which is the opposite of vibe coding. A dev who runs the same CLI with a one-line prompt (“add a hit-flash to the player sprite”), accepts the diff sight unseen, and pastes the screenshot of the result back into the next prompt is vibe coding. Same tool, different posture.
Is Claude Code vibe coding by the “accept the diff” test?
The cleanest behavioral test is the one Karpathy named explicitly: do you accept the diff without reading it. Claude Code makes this trivially easy. The CLI’s default flow is propose-edit-then-confirm; the dev presses one key to accept. There are also auto-edit modes that skip the confirmation entirely, where the agent proposes, applies, runs, and reacts in one loop. Setting up a Claude Code session in auto-edit mode and giving it a one-paragraph brief is the canonical vibe-coding setup. Setting up the same session with confirm-each-edit on and reading every proposed change is the canonical not-vibe-coding setup. The CLI supports both.
So is Claude Code vibe coding? On the auto-edit, prompt-once, run-watch-react path: yes, exactly. On the manual-confirm, review-each-diff path: no, that’s pair programming with an agent. The conflation in the public conversation comes from the fact that Claude Code is the most popular CLI surface where the vibe-coding workflow plays out, so the workflow gets named after the tool by default. The accurate way to talk about it is to keep the two layers separate. Claude Code is the agentic coding surface; vibe coding is the posture the dev adopts on top of it. That distinction matters when shopping for a vibe-coding tool because the same posture works on top of any agentic coding surface, including WizardGenie, which routes Claude Sonnet 4.6 and Opus 4.7 through the same model picker as seven other frontier models and surfaces the game-asset stack one click away.
What Claude Code adds to the vibe-coding loop in 2026
The v2.1.x release line shipped a handful of features that were specifically designed for the vibe-coding posture. The Agent view (research preview as of v2.1.139) shows every running, blocked, and finished Claude Code session in one list, accessed with the claude agents command. That means a vibe coder running three parallel agentic sessions — one on the gameplay code, one on the menu system, one on the build configuration — can scan the state of all three without switching terminals. The /goal command lets the dev set a completion condition (“the player can move, jump, and fire a fireball”) and Claude Code continues working across turns with a live overlay of elapsed time, turn count, and token consumption. The /scroll-speed command is small but telling: it’s a quality-of-life knob added because the dev is watching the agent type for long enough that the scroll speed matters. The MCP plumbing was reworked so .mcp.json edits auto-refresh without a restart and subagents carry an x-claude-code-agent-id header for tracing.
The economics are also priced for long agentic sessions. The Anthropic API documentation indexers list Claude Sonnet 4.6 at $3 input and $15 output per million tokens, with prompt caching at $0.30 per million on cache reads. Claude Opus 4.7 lists at $5 input and $25 output, with Opus 4.7 specifically using a new tokenizer that can produce up to 35% more tokens for the same input text compared to Opus 4.6 — meaning per-request bills can grow even when the rate card looks unchanged. A typical hour of agentic vibe-coding on a small game project on Sonnet 4.6 lands around $2 to $8 of API spend depending on how many files the agent reads per turn. Opus runs roughly 1.7x more for the same workflow because of the higher per-token rate. Both numbers are an order of magnitude lower than the deprecated Opus 4.0 list price ($15 / $75) was last year, which is part of why the “Claude is too expensive to vibe with” complaint from late 2024 has mostly faded.
The Planner-Executor variant: when single-model Claude Code costs add up
Long sessions still add up. The pattern that vibe coders running multi-hour agentic loops reach for is the Planner-Executor split: route the planning step (read the codebase, decide what to change, write the spec for the diff) to a top-tier reasoning model like Claude Opus 4.7 or GPT-5.5, and route the actual code-typing (drafting the diff, applying the edits, running the shell command) to a fast cheap model like DeepSeek V4 Pro, Kimi K2.5, MiniMax M2.7, Gemini 3.1 Flash, or GPT-5.5 Mini. The economics are real. Opus 4.7 is $5 input and $25 output per million tokens; DeepSeek V4 Pro lists at $0.435 input and $0.87 output at the May 2026 promo (75% off, valid through May 31, 2026; list $1.74 / $3.48). The output side is where the savings stack up — on a long agentic session the executor types the bulk of the tokens, so a 25:1 spread on the output rate translates to roughly a 1/5 single-frontier cost when the planner is Opus and the executor is DeepSeek V4 Pro.
The Planner-Executor pattern only works when the executor is genuinely cheap. Pairing two frontier-priced models defeats the purpose. Pairing Sonnet ($3 / $15) as the executor still saves something but loses most of the headline ratio, which is why the cost-conscious version of Claude Code vibe coding tends to put Sonnet on the planner side and a true cheap model on the typing side. Claude Code itself is single-model on a given session; running the Planner-Executor split inside WizardGenie exposes both halves of the pairing in one picker without juggling separate API keys or two terminals. We covered the full per-token landscape in the 2026 AI coding API pricing breakdown, refreshed on the same May verification cycle as this post.