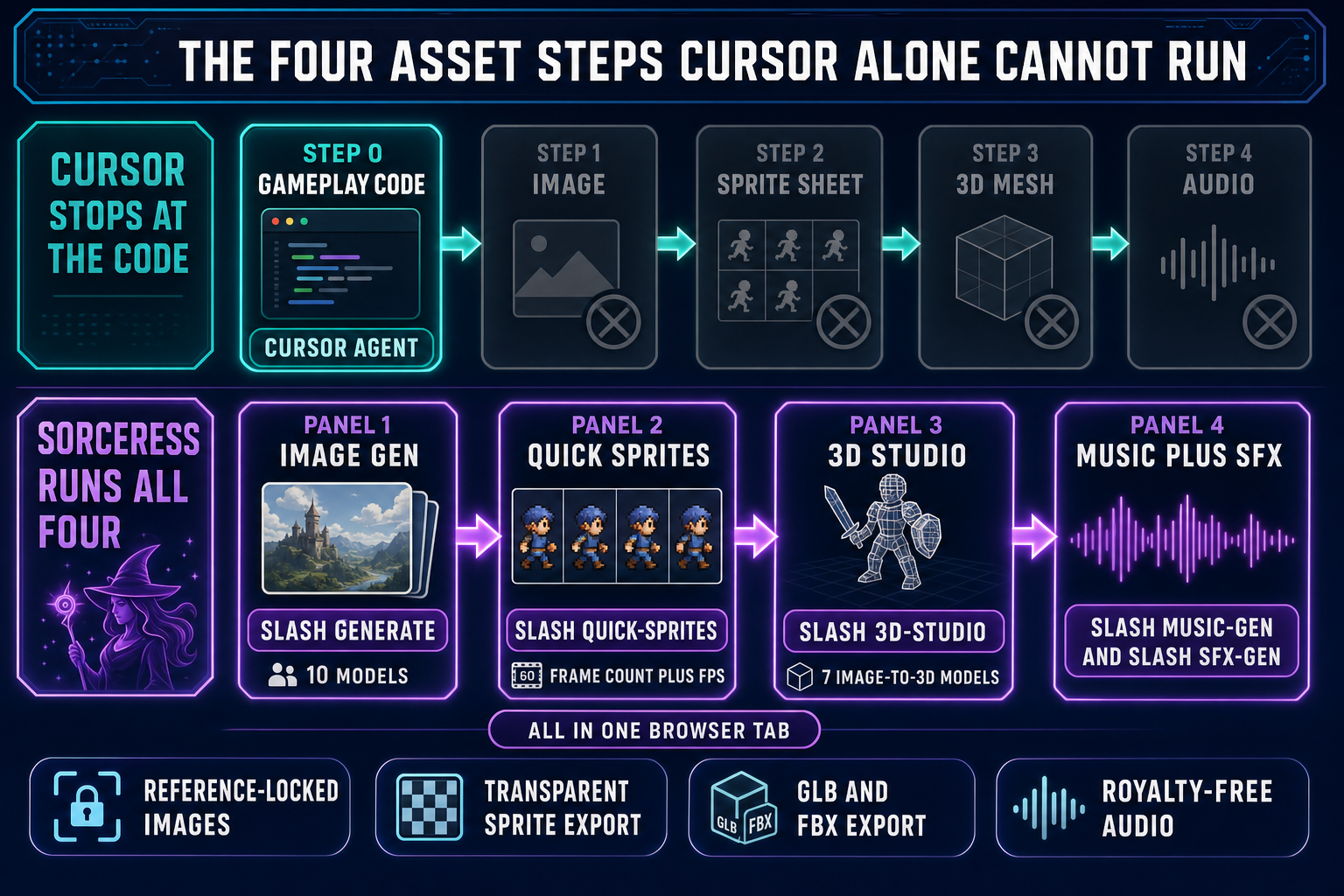
Search "cursor vibe coding" in May 2026 and the SERP is dominated by web-app demos — a Notion clone shipped over a weekend, a CRUD dashboard agentically refactored from one framework to another, a Stripe-checkout flow scaffolded in under an hour. That is what Cursor is genuinely excellent at. The reason it shows up under this query at all is that Andrej Karpathy was on Cursor when he coined "vibe coding" on February 2, 2025, and Cursor's 2.0 release on October 29, 2025 shipped Composer plus a multi-agent interface that doubled down on the agentic loop. The catch — and the gap this post fills — is that the same workflow that ships a CRUD app does not ship a game, because games are not just code. Verified May 16, 2026 against Cursor's published changelogs, the Anthropic and DeepSeek pricing aggregator listings, and the WizardGenie model lineup in src/app/_home-v2/_data/tools.ts.
What "cursor vibe coding" actually means in 2026
The phrase has two halves and both matter. Vibe coding is the workflow Andrej Karpathy described on X on February 2, 2025 — "fully give in to the vibes, embrace exponentials, and forget that the code even exists." The dev describes intent in plain English, the model proposes a diff, the dev accepts without line-editing, the build runs, the dev watches the screen, and the result (the success or the error or the off-by-one feeling) gets pasted back into the next prompt. Karpathy's setup was Cursor Composer routed to a Claude Sonnet model, often controlled by voice through SuperWhisper. Independent analyst Simon Willison picked up the term four days later and noted the same posture: accept the diff sight unseen, run, react. By the end of 2025 Collins Dictionary had named "vibe coding" its word of the year.
Cursor is the AI-first editor that became the default surface for that workflow because it shipped agentic features earlier and more aggressively than any general-purpose IDE. The 2.0 release on October 29, 2025 added Composer (Cursor's own agentic coding model, 4x faster than comparable frontier models on most turns), a multi-agent interface that runs up to eight agents in parallel on git worktrees, a generally-available browser-in-editor, sandboxed terminals, and voice-mode agent control. The 2.2 release on December 10, 2025 added Debug Mode and multi-agent judging. The 3.x line has unified local agents and cloud agents in one sidebar and added a web app at cursor.com/agents that lets a dev assign background tasks from a phone. So "cursor vibe coding" as a query usually means: the Karpathy-style intent-first loop, running on the Cursor editor, sometimes with Composer doing the thinking and sometimes with a routed Claude or GPT model behind the prompt.
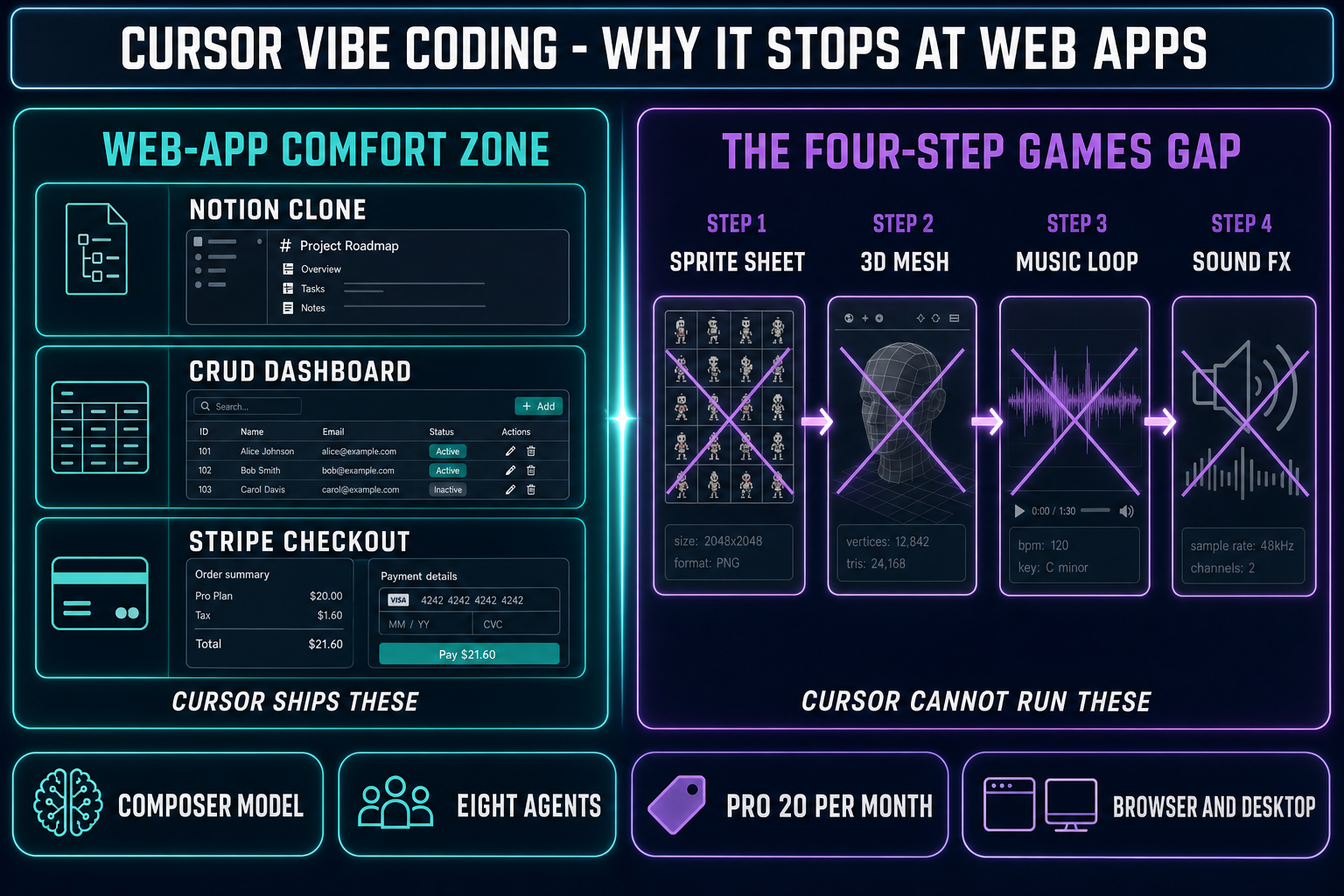
Why Cursor became the default vibe-coding surface for web apps
Three things, none of them mysterious. The first is shape fit. Cursor is a fork of VS Code. The codebases that VS Code is dominant on — TypeScript, React, Next.js, Tailwind, Node, Python, FastAPI, Django, Rails — are the exact codebases on which agentic frontier models perform best, because the training data is largest and the surface area is smallest. A Next.js app is mostly text files, mostly server-side request handlers and client-side components, mostly with one obvious right answer per change. That is what vibe coding rewards: every diff is testable in one browser refresh and the dev's eyes are a reasonable oracle for "does the form submit?" or "did the layout shift?".
The second is agentic primitives. Cursor 2.0 shipped Composer alongside the multi-agent interface specifically so a long-running session would not block the editor. Background Agents run as separate processes; the dev kicks off a refactor and goes back to writing the next feature while the agent's progress streams into the sidebar with a Running / Paused / Completed / Failed status. Cursor 3 pulled local and cloud agents into the same view. That removes the "wait for the agent" tax that older AI-coding workflows charged. The Karpathy loop — describe, accept, run, watch, react — gets faster because the loop is non-blocking.
The third is model routing. Cursor's Pro tier is $20/month with $20 of model usage credit on top of the editor; Pro+ at $60/month bumps that to $70 of usage; Ultra at $200/month bumps it to roughly $400 of usage. Inside the editor the dev picks the model per turn — Composer for the cheap fast iteration, Claude Sonnet 4.6 for the careful diff, Claude Opus 4.7 for the hard refactor, GPT-5.5 for the second opinion. The dev does not have to think about API keys or billing; the editor does the routing. That is the killer feature for web-app vibe coding and the reason most "cursor vibe coding" YouTube demos show a dev shipping a SaaS landing page in 30 minutes.
The cursor vibe coding workflow, end to end
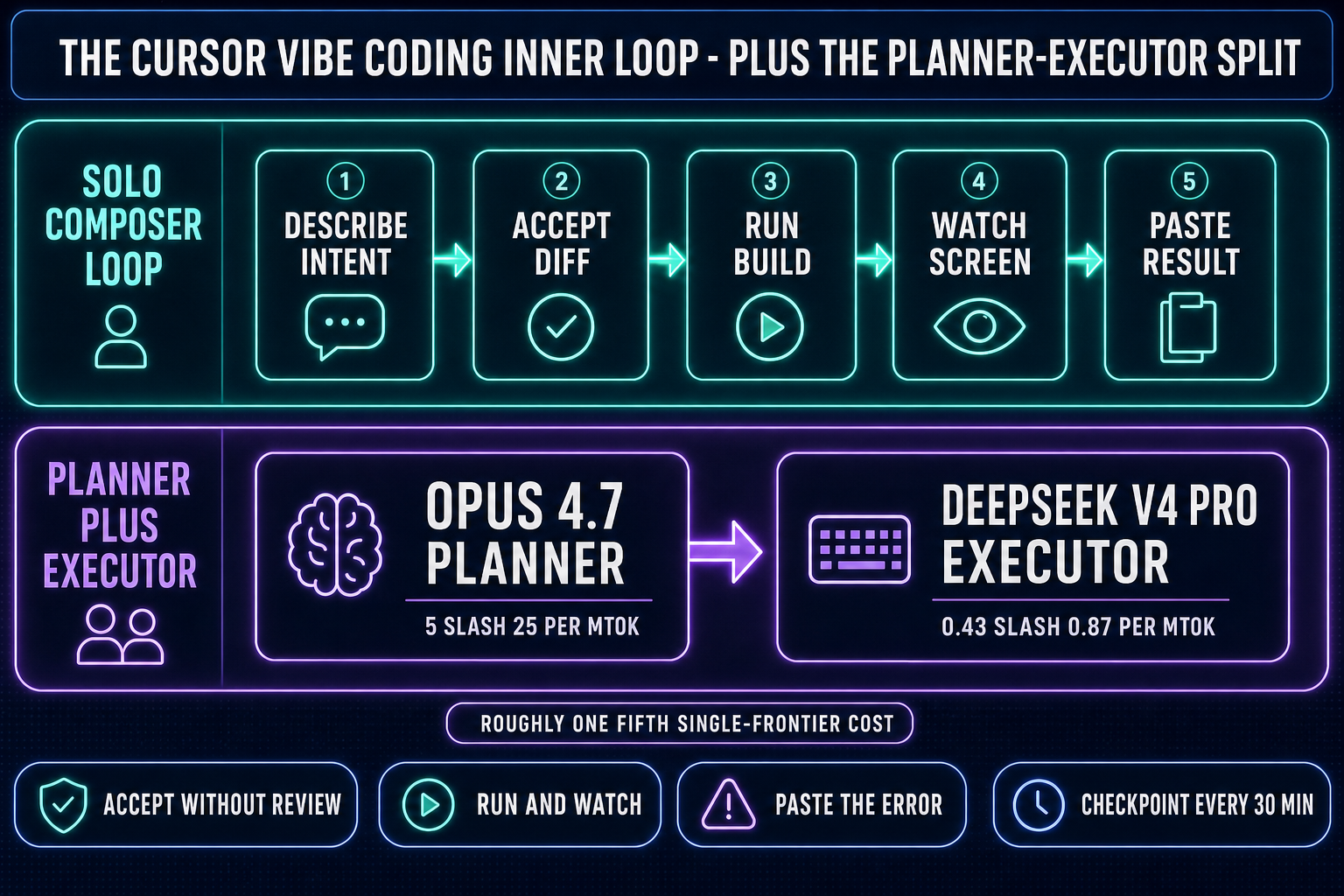
Pulled apart, the loop is short enough to fit on a sticky note:
- Describe the change in one or two sentences. Not pseudocode, not function signatures — intent. "When the user clicks submit, validate the email, post to /api/signup, and redirect to /welcome on success."
- Let the agent propose a diff. Composer or a routed Claude or GPT model reads the relevant files, decides which ones to edit, and shows the diff inline.
- Accept the diff without line-editing it. This is the controversial step. Vibe coders accept and run; line-by-line review is the prior workflow.
- Run the app and watch. Either the form submits, or it doesn't, or the build breaks.
- Paste the result back. If the build broke, paste the error. If the form submitted but the redirect was wrong, describe the wrong-ness. The agent proposes the next diff.
For a web app the loop converges fast because the failure surface is small and legible. A 500 from /api/signup has a stack trace that points to one file and one line. A wrong redirect is a one-line config change. A broken validator is a regex tweak. That is the shape of the work where cursor vibe coding shines and the shape of the work that fills the SERP results for the query.
The Planner-Executor pattern: expensive thinker, cheap typer
Long agentic sessions on a single frontier model burn money in a way that becomes obvious after the first $40 day. The Planner-Executor split is the answer cost-conscious vibe coders reach for: route the planning step (read the codebase, decide what to change, write the spec for the diff) to a top-tier reasoning model like Claude Opus 4.7 or GPT-5.5, and route the actual code-typing (drafting the diff, applying the edits, running the shell command) to a fast cheap model like DeepSeek V4 Pro, Kimi K2.5, MiniMax M2.7, Gemini 3.1 Flash, or GPT-5.5 Mini. The economics are real. Opus 4.7 runs $5 input and $25 output per million tokens; DeepSeek V4 Pro is around $0.435 input and $0.87 output at the May 2026 promo (list price $1.74 / $3.48), which expires May 31, 2026.
The output side is where the savings stack up — on a long agentic session the executor types the bulk of the tokens, so a roughly 28:1 spread on the output rate translates to about a 1/5 single-frontier cost when the planner is Opus and the executor is DeepSeek V4 Pro. The pattern only works when the executor is genuinely cheap. Pairing two frontier-priced models defeats the purpose — putting Sonnet 4.6 (around $3 / $15 per Mtok input/output) on the typing side erases roughly four-fifths of the cost advantage. Cursor's Plan Mode in Background does this kind of split inside one editor; WizardGenie exposes both halves explicitly in the model picker so a single project can run Opus-as-planner with DeepSeek-as-executor. We unpacked the full per-token landscape in the 2026 AI coding API pricing breakdown, refreshed on the same May verification cycle as this post.